Що таке векторна база даних?
By Sean Chen, 10 листопада 2023 р.

Ця серія статей "Нехай AI пояснить AI" повністю написана за допомогою великих мовних моделей, таких як GPT-4, під людським наглядом. Серія надає знання про AI у доступній формі для фахівців з різним досвідом. Перша частина пояснює значення знань для бізнесу, а друга частина розкриває технічні деталі.
Коли бізнес стикається з ерою великих даних, векторні бази даних стають маяком у світі неструктурованих даних, освітлюючи шлях до швидкого пошуку інформації. Ця стаття допоможе вам зрозуміти, як ця технологія працює і яке значення вона має для бізнесу.
Принципи та сутність векторних баз даних
Векторні бази даних використовують математичні "вектори" для зберігання інформації. Давайте розглянемо приклад з повсякденного життя: уявіть, що у вашій кімнаті багато різнокольорових кульок, кожна з яких представляє певні дані. Тепер ви хочете розмістити ці кульки на полицях так, щоб їх розташування відображало кольорові характеристики кожної кульки. Ви вирішуєте використовувати "кольорову карту" у вигляді записника, щоб допомогти знайти місце для кожної кульки. На цій карті кульки схожих кольорів будуть розташовані ближче один до одного, а різнокольорові — далі один від одного.
Векторна база даних працює за тим же принципом: вона спочатку перетворює різні дані (наприклад, текст, зображення або звук) у математичні вектори (як згадані кульки). Ці вектори мають свої позиції у багатовимірному просторі, як кульки на полицях. Коли ви хочете швидко знайти дані, схожі на певні, векторна база даних допоможе вам знайти найближчі вектори у цьому багатовимірному просторі (як знайти кульки найближчого кольору).
Простіше кажучи, це метод абстрагування характеристик даних у вигляді точок у просторі, а потім обчислення відстаней між цими точками для швидкого знаходження схожих даних.
Чому це важливо
Уявіть, що ви шукаєте конкретну книгу у великій бібліотеці, і якщо всі книги розташовані лише за автором або назвою, вам може знадобитися багато часу на пошук. Але якщо книги розташовані за "змістовною схожістю", то книга, яку ви шукаєте, буде поруч з книгами на схожу тему, що значно полегшить пошук. Це і є важливість векторних баз даних: вони значно підвищують ефективність пошуку та аналізу великих обсягів даних.
Як використовувати
Для використання векторної бази даних спочатку потрібен набір даних, наприклад, текст, зображення або звук. Ці дані перетворюються у "вектори" за допомогою "моделей машинного навчання". Потім ці вектори зберігаються у векторній базі даних. Коли користувач робить запит, цей запит також перетворюється у вектор, і база даних швидко знаходить дані, вектори яких найближчі до запиту, надаючи користувачеві потрібну інформацію.
Застосування
Векторні бази даних використовуються компаніями, які обробляють великі обсяги даних, у різних галузях. Це включає технологічні компанії, фінансові установи, медичні заклади та навіть роздрібні торговці. Будь-яка організація, яка потребує швидкого знаходження необхідної інформації у "величезному морі неструктурованих даних", може використовувати векторні бази даних.
Переваги
Переваги векторних баз даних полягають у їх високій ефективності та точності. Вони можуть швидко обробляти та знаходити великі обсяги складних даних, що часто неможливо при використанні традиційних баз даних. Крім того, векторні бази даних відмінно справляються з обробкою нечітких запитів, що є важливим для застосувань у машинному навчанні та штучному інтелекті.
Виклики
Необхідність у великій кількості обчислювальних ресурсів, особливо при обробці дуже великих наборів даних. По-друге, вони вимагають високоспеціалізованих знань для налаштування та обслуговування. Нарешті, конфіденційність та безпека даних також є важливими аспектами.
Після отримання базового розуміння векторних баз даних, давайте розглянемо їх роботу за допомогою графіків та реальних прикладів!
Візуалізація векторних баз даних
Ми почнемо з базових концептуальних діаграм, щоб пояснити принципи роботи векторних баз даних, а потім перейдемо до конкретного прикладу. Нижче наведено опис цих двох частин:
Діаграми пояснення принципів роботи
- Діаграма перетворення векторів: ця діаграма показує, як текстові, зображення або звукові дані перетворюються у вектори.
- Діаграма векторного простору: у багатовимірному просторі кожна точка представляє вектор, ця діаграма показує, як ці точки групуються разом за схожістю. Ми можемо використовувати різні кольори точок для позначення різних категорій даних.
- Діаграма процесу обробки запитів: від введення запиту користувачем до отримання результатів, ця діаграма показує весь процес пошуку. Це включає введення запиту користувачем, процес перетворення у вектор, процес відповідності векторів у базі даних та кінцеве повернення схожих результатів користувачеві.
Конкретний аналіз випадку
Припустимо, що є одна електронна комерційна компанія, яка хоче підвищити точність та ефективність своєї "системи рекомендацій продуктів", щоб, коли користувач шукає продукт, він міг швидко знайти та рекомендувати найбільш релевантні продукти.
Кроки виконання випадку:
- Збір даних: компанія збирає дані зі своєї бази даних продуктів, включаючи описи продуктів, зображення та відгуки клієнтів.
- Перетворення векторів: за допомогою моделі машинного навчання кожен опис продукту та зображення перетворюються у вектори.
- Створення векторної бази даних: ці вектори зберігаються у векторній базі даних, і створюється система швидкого пошуку.
- Обробка запиту користувача: коли користувач вводить ключове слово, наприклад, "спортивне взуття", система перетворює цей запит у вектор і шукає найбільш схожі вектори у векторній базі даних.
- Повернення результатів: система перетворює вектори з найвищою схожістю назад у інформацію про продукти та показує їх користувачеві.
Ми використовуватимемо Python для опису цих концепцій. Давайте подивимося на першу діаграму: діаграма перетворення векторів.
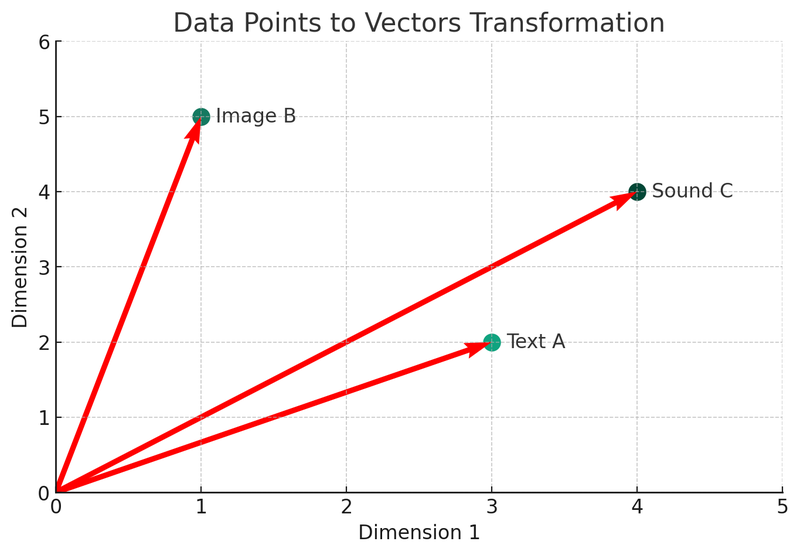
На цій ілюстрації ми можемо побачити три різні типи даних (текст A, зображення B, звук C), які перетворюються у вектори у двовимірному просторі. Кожна точка представляє вектор, тобто математичне представлення початкових даних. Цей процес є основою для створення індексу та механізму пошуку у векторній базі даних.
Далі ми створимо другу діаграму: діаграма векторного простору, яка показує, як ці точки даних (тепер вектори) групуються у багатовимірному просторі за схожістю.
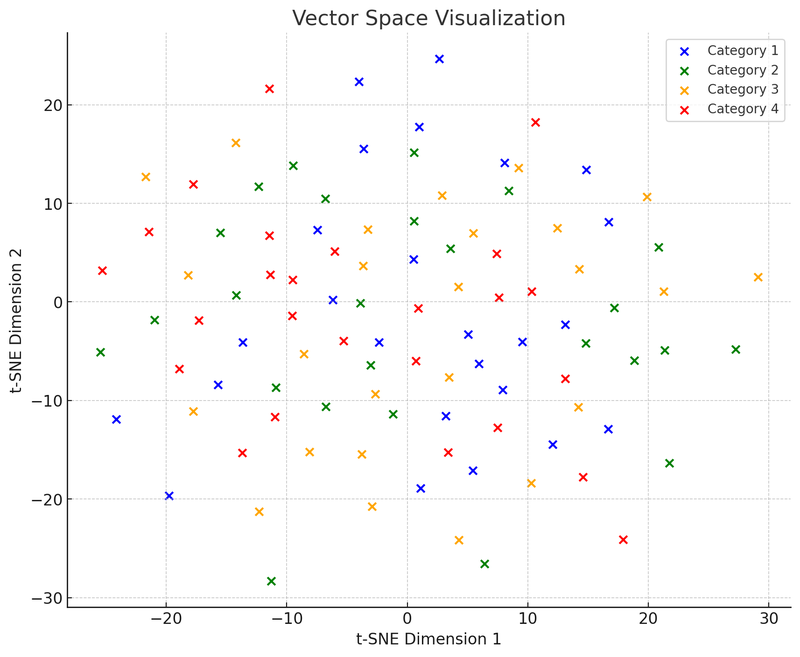
На цій ілюстрації векторного простору ми використовували t-SNE (t-distributed Stochastic Neighbor Embedding), популярну техніку зниження розмірності, яка допомагає проектувати високовимірні дані у двовимірний або тривимірний простір для візуалізації. Ця діаграма показує розподіл 100 точок даних (спочатку у 50-вимірному просторі), знижених до двовимірного простору. Припустимо, що ці точки поділені на чотири категорії, кожна категорія позначена різним кольором. Така візуалізація допомагає зрозуміти, як працюють векторні бази даних: вони можуть групувати схожі точки даних (тобто вектори) разом на основі відносної відстані між ними. Ця особливість дозволяє векторним базам даних швидко знаходити "сусідні" точки під час пошуку, тобто ті, що найбільш схожі на запит.
Для моделювання системи рекомендацій продуктів електронної комерції ми створимо спрощений приклад, який включає: набір продуктів-векторів та вектор запиту користувача. Ми візуалізуємо розподіл цих продуктів-векторів у векторному просторі та покажемо, як "вектор запиту" користувача знаходить "найближчий продукт-вектор", щоб пояснити застосування векторних баз даних у системах рекомендацій продуктів.
Візуалізований аналіз випадку
Спочатку ми генеруємо набір симульованих продуктів-векторів, а потім визначаємо вектор запиту користувача. Потім ми покажемо на діаграмі, як цей вектор запиту знаходить найближчий продукт-вектор у векторному просторі.
Давайте розпочнемо цей процес.
На цій діаграмі сині точки представляють різні продукти на платформі електронної комерції, кожен продукт має двовимірний вектор характеристик. Червона точка — це запит користувача, який також перетворено у двовимірний вектор. Ми використовували структуру даних K-D дерево (KDTree) для швидкого знаходження "найближчого продукту-вектора" до запиту користувача.
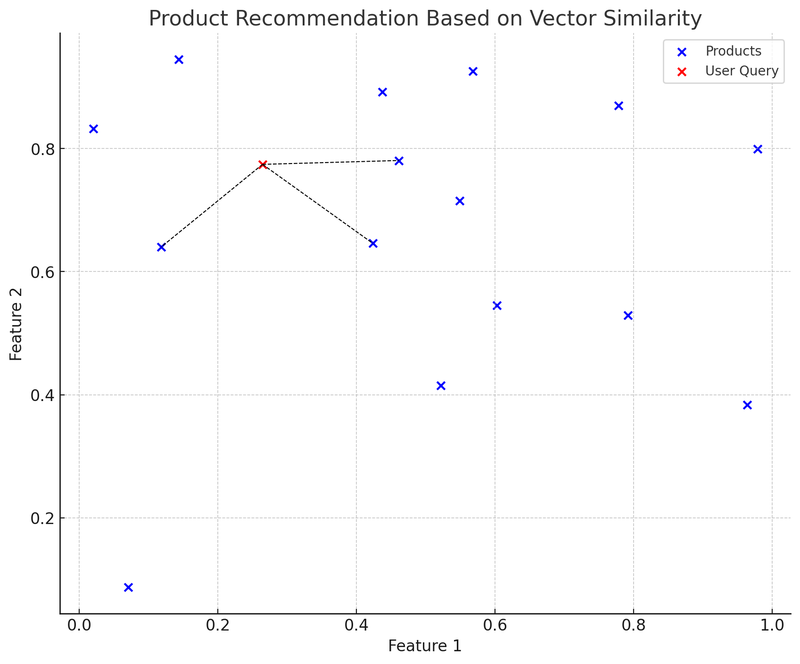
На цій діаграмі чорна пунктирна лінія від вектора запиту користувача (червона точка) до найближчого продукту-вектора показує, що система рекомендацій буде рекомендувати ці продукти користувачу на основі схожості векторів. Це спрощений приклад застосування векторних баз даних: користувач робить запит, система перетворює запит у вектор і швидко знаходить найбільш схожий продукт-вектор у векторній базі даних, щоб рекомендувати відповідні продукти користувачу.
Перевага цього методу полягає у швидкості та відносній точності рекомендацій, оскільки вони базуються на математичних розрахунках характеристик продуктів, а не лише на відповідності ключових слів. Виклики включають: як вибрати та налаштувати вектори характеристик, щоб найкраще описати та представити характеристики продуктів, а також як вирішити проблему "холодного старту" для нових продуктів або рідкісних запитів.
Висновок
У сучасному бізнес-середовищі, орієнтованому на дані, векторні бази даних обробляють та знаходять великі обсяги багатовимірних даних у унікальний та потужний спосіб, роблячи їх ідеальним вибором для застосувань у штучному інтелекті та машинному навчанні. Від підвищення релевантності результатів пошуку до стимулювання персоналізованих рекомендацій продуктів, векторні бази даних швидко стають цінним інструментом для інженерів даних та технологічних новаторів у різних галузях. За допомогою ілюстрацій та аналізу випадків від Appar Technologies ми сподіваємося чітко пояснити, як працюють векторні бази даних і чому вони можуть надавати такі швидкі та точні результати.
Векторні бази даних демонструють, наскільки потужними можуть бути інструменти та застосування, коли люди починають розуміти та використовувати дані по-новому. З розвитком технологій ми можемо очікувати, що векторні бази даних відіграватимуть ще більш важливу роль у майбутній обробці та аналізі даних.
Якщо вас цікавить, як генеративний AI може створювати високоякісні статті, інтегрувати великі мовні моделі у продукти або внутрішні процеси компанії, ви можете зв'язатися з експертами з генеративного AI Appar Technologies, hello@appar.com.tw для консультації.