Vad är en vektordatabas?
By Sean Chen, 10 november 2023

Denna artikelserie, 'Låt AI förklara AI', är helt skriven av stora språkmodeller som GPT-4 under mänsklig övervakning. Serien syftar till att ge arbetare från olika bakgrunder en enkel påfyllning av AI-relaterad kunskap. Den första delen förklarar betydelsen av denna kunskapspunkt för affärsvärlden, medan den andra delen förklarar mer djupgående tekniska detaljer.
När affärsvärlden möter den stora datans era, blir vektordatabaser en ledstjärna i den ostrukturerade datavärlden, som lyser upp vägen för snabb informationssökning. Denna artikel kommer att ge dig en djupare förståelse för hur denna teknik fungerar och dess betydelse och påverkan på företagsvärlden.
Principen och essensen av vektordatabaser
Vektordatabaser använder matematiska 'vektorer' för att lagra information. Låt oss använda ett exempel från vardagen för att förklara: Anta att ditt rum är fyllt med små bollar i olika färger, där varje boll representerar en typ av data. Nu vill du placera bollarna på specifika platser på en bokhylla, och dessa platser ska kunna återspegla varje bolls färgegenskaper. Så du bestämmer dig för att använda en 'färgkarta' anteckningsbok för att hjälpa dig hitta varje bolls plats. I denna anteckningsbok placeras bollar med liknande färger närmare varandra, medan olika färger placeras längre ifrån varandra.
Vektordatabaser fungerar på samma sätt. De omvandlar olika typer av data (som text, bilder eller ljud) till matematiska vektorer (som de tidigare nämnda bollarna). Dessa vektorer har sina egna positioner i ett flerdimensionellt rum, precis som bollarna på bokhyllan. När du snabbt vill hitta data som liknar en viss data, hjälper vektordatabasen dig att hitta de vektorer som ligger närmast i detta flerdimensionella rum (precis som att hitta bollar med liknande färger).
Enkelt uttryckt, genom att använda matematiska metoder, abstraheras dators egenskaper till punkter i rymden, och genom att beräkna avståndet mellan dessa punkter kan man snabbt hitta liknande data.
Varför det är viktigt
Föreställ dig att du letar efter en specifik bok i ett stort bibliotek. Om varje bok bara kan ordnas efter författare eller titel, kan du behöva spendera mycket tid på att leta. Men om böckerna är ordnade efter 'innehållsrelevans', kommer den bok du vill ha att placeras tillsammans med böcker med liknande ämnen, vilket gör det mycket snabbare att hitta. Det är här vektordatabaser kommer in: de kan avsevärt öka effektiviteten i att söka och analysera stora mängder data.
Hur man använder
När du använder en vektordatabas behöver du först en uppsättning data, som text, bilder eller ljud. Dessa data omvandlas till 'vektorer' genom en 'maskininlärningsmodell'. Sedan lagras dessa vektorer i vektordatabasen. När en användare gör en förfrågan, omvandlas denna förfrågan också till en vektor, och databasen hittar snabbt de datavektorer som ligger närmast denna förfrågningsvektor, vilket ger användaren den information de behöver.
Tillämpningar
Vektordatabaser används av företag i olika branscher som behöver hantera stora mängder data. Detta inkluderar teknikföretag, finansiella institutioner, vårdinrättningar och till och med återförsäljare. Alla organisationer som behöver 'snabbt hitta den information de behöver i ett hav av svårstrukturerad data' kan använda vektordatabaser.
Fördelar
Fördelarna med vektordatabaser ligger i deras höga effektivitet och noggrannhet. De kan snabbt bearbeta och hämta stora mängder komplex data, vilket ofta är omöjligt med traditionella databaser. Dessutom är vektordatabaser mycket bra på att hantera oskarpa förfrågningar, vilket är avgörande för maskininlärning och AI-applikationer.
Utmaningar
De kräver stora mängder beräkningsresurser, särskilt när man hanterar mycket stora datamängder. Dessutom kräver de högspecialiserad kunskap för att ställa in och underhålla. Slutligen är dataintegritet och säkerhet också viktiga överväganden.
Efter att ha fått en grundläggande förståelse för vektordatabaser, låt oss nu använda diagram och verkliga exempel för att få en mer konkret förståelse för hur vektordatabaser fungerar!
Introduktion till vektordatabaser genom visuella diagram
Vi börjar med grundläggande konceptdiagram för att förklara hur vektordatabaser fungerar och fortsätter med en konkret fallstudie. Följande är en beskrivning av dessa två delar:
Diagramförklaring av funktionsprincipen
- Vektoromvandlingsdiagram: Detta diagram visar hur text-, bild- eller ljuddata omvandlas till vektorer.
- Vektorrumsdiagram: I ett flerdimensionellt rum representerar varje punkt en vektor, och detta diagram visar hur dessa punkter grupperas baserat på likhet. Vi kan använda punkter i olika färger för att representera olika datakategorier.
- Förfrågningsprocessdiagram: Från användarinmatning av en förfrågan till att få resultat, visar detta flödesdiagram hela sökprocessen. Detta inkluderar användarinmatning av förfrågan, omvandling till vektor, matchningsprocessen i databasen och slutligen de liknande resultaten som returneras till användaren.
Konkreta fallstudier
Anta att ett e-handelsföretag vill förbättra noggrannheten och effektiviteten i sitt 'produktrekommendationssystem', med målet att snabbt hitta och rekommendera de mest relevanta produkterna när användare söker efter produkter.
Fallstudie steg:
- Datainsamling: Företaget samlar in data från sin produktdatabas, inklusive produktbeskrivningar, bilder och kundrecensioner.
- Vektoromvandling: Använd en maskininlärningsmodell för att omvandla varje produkts beskrivning och bild till vektorer.
- Bygg en vektordatabas: Lagra dessa vektorer i en vektordatabas och skapa ett snabbt söksystem.
- Användarförfrågningshantering: När en användare anger ett nyckelordsförfrågan, till exempel: sportskor, omvandlar systemet denna förfrågan till en vektor och söker efter den mest liknande vektorn i vektordatabasen.
- Returnera resultat: Systemet omvandlar de mest liknande produktvektorerna tillbaka till produktinformation och visar dem för användaren.
Vi kommer att använda Python för att beskriva dessa koncept. Låt oss titta på det första diagrammet: vektoromvandlingsdiagrammet.
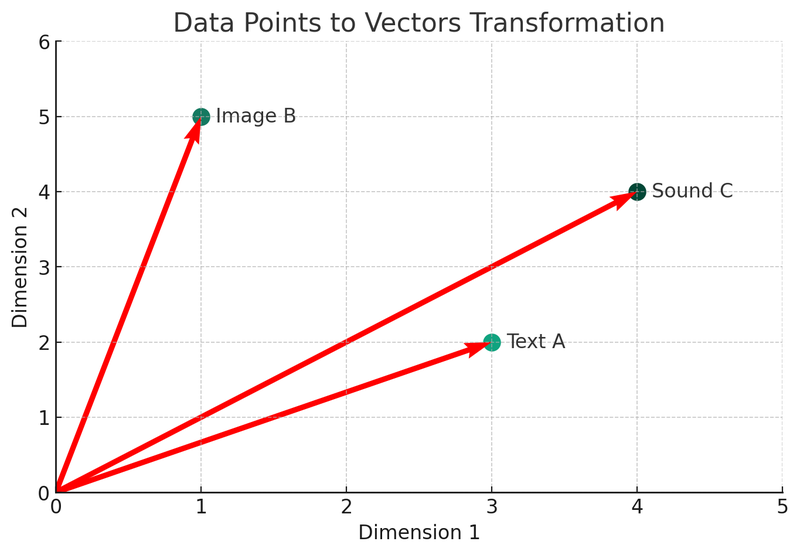
I denna illustration kan vi se tre olika datatyper (text A, bild B, ljud C) omvandlas till vektorer i ett tvådimensionellt rum. Varje punkt representerar en vektor, vilket är den matematiska representationen av den ursprungliga datan. Denna process är kärnan i att bygga index och sökfunktioner i en vektordatabas.
Härnäst kommer vi att rita det andra diagrammet: vektorrumsdiagrammet, som visar hur dessa datapunkter (nu vektorer) grupperas i ett flerdimensionellt rum baserat på likhet.
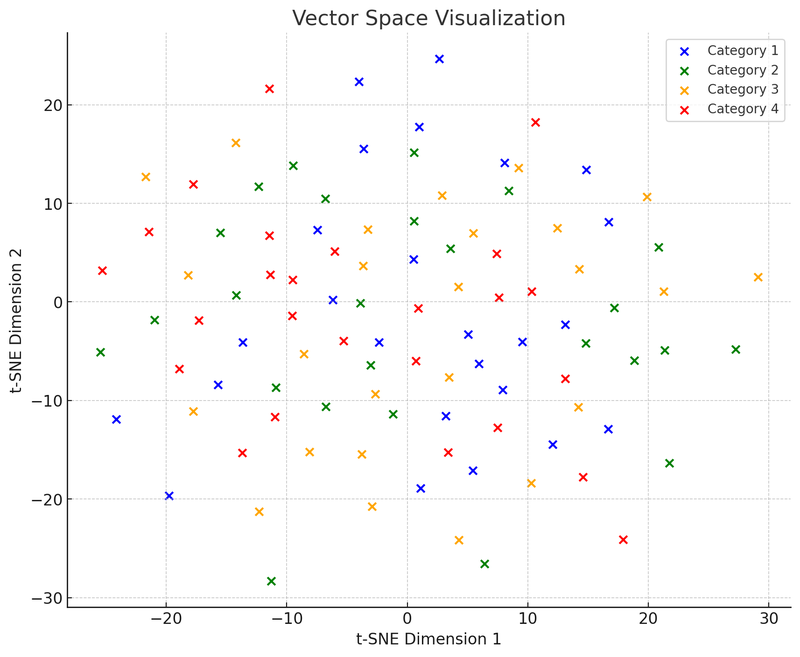
I denna visualisering av vektorrummet använder vi t-SNE (t-distributed Stochastic Neighbor Embedding), en vanlig dimensionreduceringsteknik som hjälper oss att projicera högdimensionell data till två- eller tredimensionellt utrymme för visualisering. Detta diagram visar fördelningen av 100 datapunkter (ursprungligen i ett 50-dimensionellt rum) efter att de reducerats till tvådimensionellt utrymme. Anta att dessa punkter är indelade i fyra kategorier, där varje kategori representeras av olika färger. Sådan visualisering hjälper till att förstå hur vektordatabaser fungerar: de kan gruppera liknande datapunkter baserat på det relativa avståndet mellan datapunkterna (dvs. vektorer). Denna egenskap gör att vektordatabaser snabbt kan hitta 'grannar', dvs. de datapunkter som är mest liknande en förfrågan.
För att simulera ett e-handelsföretags produktrekommendationssystem kommer vi att skapa ett förenklat exempel som innehåller: en uppsättning produktvektorer och en användarförfrågningsvektor. Vi kommer att använda visualisering för att visa fördelningen av dessa produktvektorer i vektorrummet och hur användarens 'förfrågningsvektor' hittar 'närmaste produktvektor', för att illustrera tillämpningen av vektordatabaser i produktrekommendationssystem.
Visualiserad fallstudie
Först genererar vi en uppsättning simulerade produktvektorer och definierar sedan en användarförfrågningsvektor. Därefter kommer vi att
använda ett diagram för att visa hur denna förfrågningsvektor lokaliserar och hittar de närmaste produktvektorerna i vektorrummet.
Låt oss börja denna process.
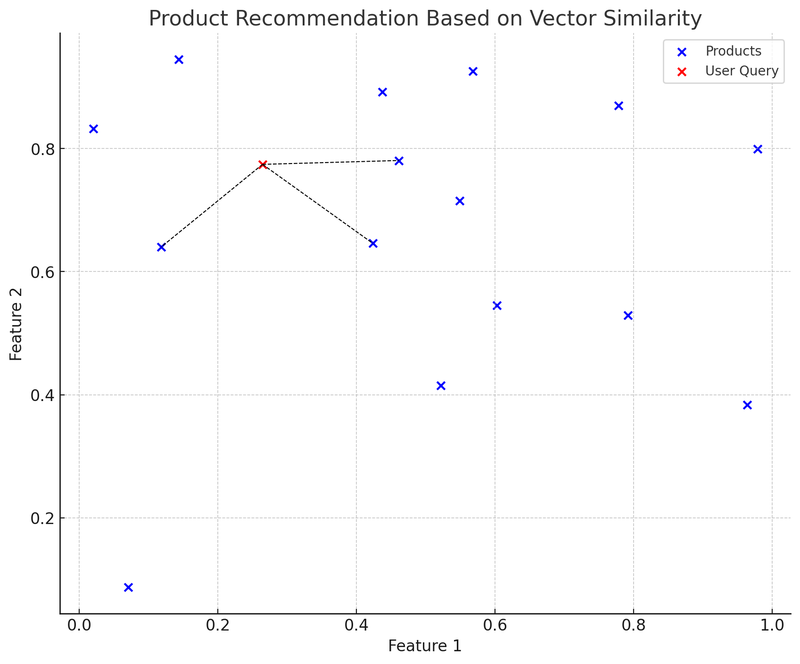
I detta diagram representerar de blå punkterna olika produkter på e-handelsplattformen, där varje produkt har en tvådimensionell funktionsvektor. Den röda punkten är en användarförfrågan, som också har omvandlats till en tvådimensionell vektor. Vi använder datastrukturen K-D träd (KDTree) för att snabbt hitta de produktvektorer som är närmast användarförfrågan.
I diagrammet representerar den svarta streckade linjen från användarförfrågningsvektorn (röd punkt) till den närmaste produktvektorn: rekommendationssystemet kommer att rekommendera dessa produkter till användaren baserat på vektorernas likhet. Detta är ett förenklat exempel på hur vektordatabaser används i praktiken: användaren gör en förfrågan, systemet omvandlar förfrågan till en vektor och hittar snabbt den mest liknande produktvektorn i vektordatabasen, vilket rekommenderar relevanta produkter till användaren.
Fördelarna med denna metod är att rekommendationerna är snabba och relativt exakta, eftersom de baseras på matematiska beräkningar av produktfunktioner, inte bara nyckelordsanpassning. Utmaningar inkluderar: hur man väljer och justerar funktionsvektorer för att bäst beskriva och representera produktfunktioner, samt hur man hanterar 'kallstart'-problem för nya produkter eller mindre vanliga förfrågningar.
Slutsats
I dagens datadrivna affärsmiljö hanterar och hämtar vektordatabaser stora mängder flerdimensionell data på ett unikt och kraftfullt sätt, vilket gör dem till ett idealiskt val för AI- och maskininlärningsapplikationer. Från att förbättra relevansen av sökresultat till att driva personliga produktrekommendationer, blir vektordatabaser snabbt ett värdefullt verktyg för dataingenjörer och teknologiska innovatörer i olika branscher. Genom Appar Technologies illustrationer och fallstudier hoppas vi kunna förklara hur vektordatabaser fungerar och varför de kan ge så snabba och exakta resultat.
Vektordatabaser visar hur kraftfulla verktyg och applikationer kan skapas när människor förstår och använder data på nya sätt. Med den fortsatta utvecklingen av teknik kan vi förvänta oss att vektordatabaser kommer att spela en ännu mer avgörande roll i framtida databehandling och analysarbete.
Om du är intresserad av hur generativ AI kan skapa högkvalitativa artiklar, integrera stora språkmodeller i produkter eller interna företagsprocesser, kan du kontakta generativ AI-expert Appar Technologies, hello@appar.com.tw för att boka en konsultation.