Что такое векторная база данных?
By Sean Chen, 10 ноября 2023 г.

Эта серия статей под названием «Пусть ИИ объяснит ИИ» полностью написана с использованием больших языковых моделей, таких как GPT-4, под человеческим контролем. Серия предназначена для того, чтобы работники с разным опытом могли легко пополнить свои знания об ИИ. В первой части объясняется значение этой темы для бизнеса, а во второй части рассматриваются более глубокие технические детали.
Когда бизнес сталкивается с приходом эпохи больших данных, векторные базы данных становятся маяком в мире неструктурированных данных, освещая путь к быстрому поиску информации. Эта статья поможет вам глубже понять, как работает эта технология и какое значение она имеет для бизнеса.
Принципы и суть векторных баз данных
Векторные базы данных используют математические «векторы» для хранения информации. Давайте приведем пример из жизни: представьте, что в вашей комнате много разноцветных шариков, и каждый шарик представляет собой определенные данные. Теперь вы хотите разместить шарики на полке в определенных местах, чтобы эти места отражали цветовые характеристики каждого шарика. Вы решаете использовать «цветовую карту», чтобы помочь вам найти место для каждого шарика. В этой записной книжке шарики схожих цветов будут расположены ближе друг к другу, а шарики разных цветов — дальше друг от друга.
Векторные базы данных работают по тому же принципу: они сначала преобразуют различные данные (например, текст, изображения или звук) в математические векторы (как упомянутые шарики). Эти векторы имеют свои позиции в многомерном пространстве, как шарики на полке. Когда вы хотите быстро найти данные, наиболее похожие на определенные данные, векторная база данных поможет вам найти в этом многомерном пространстве векторы, расположенные ближе всего (как если бы вы искали шарики с наиболее похожими цветами).
Проще говоря, это метод абстрагирования характеристик данных в виде точек в пространстве, а затем вычисления расстояний между этими точками для быстрого нахождения схожих данных.
Почему это важно
Представьте, что вы ищете определенную книгу в большой библиотеке. Если книги расположены только по авторам или названиям, вам может потребоваться много времени на поиск. Но если книги расположены по «содержательной релевантности», то нужная вам книга будет находиться рядом с книгами на схожие темы, и поиск станет намного быстрее. Это и есть важность векторных баз данных: они значительно повышают эффективность поиска и анализа больших объемов данных.
Как использовать
При использовании векторных баз данных сначала необходимо иметь набор данных, например, текст, изображения или звук. Эти данные преобразуются в «векторы» с помощью «моделей машинного обучения». Затем эти векторы хранятся в векторной базе данных. Когда пользователь делает запрос, этот запрос также преобразуется в вектор, и база данных быстро находит данные, вектор которых наиболее близок к запросу, предоставляя пользователю необходимую информацию.
Применение
Векторные базы данных используются компаниями из различных отраслей, которым необходимо обрабатывать большие объемы данных. Это включает технологические компании, финансовые учреждения, медицинские учреждения и даже розничных продавцов. Любая организация, которой нужно быстро находить необходимую информацию в «море неструктурированных данных», может использовать векторные базы данных.
Преимущества
Преимущества векторных баз данных заключаются в их высокой эффективности и точности. Они могут быстро обрабатывать и извлекать большие объемы сложных данных, что часто невозможно при использовании традиционных баз данных. Кроме того, векторные базы данных отлично справляются с обработкой нечетких запросов, что имеет решающее значение для приложений машинного обучения и искусственного интеллекта.
Проблемы
Требуются значительные вычислительные ресурсы, особенно при обработке очень больших наборов данных. Кроме того, для их настройки и обслуживания необходимы высокоспециализированные знания. Наконец, конфиденциальность и безопасность данных также являются важными аспектами.
После того как вы получили базовое представление о векторных базах данных, давайте перейдем к более конкретному пониманию их работы с помощью графиков и реальных примеров!
Введение в векторные базы данных через визуальные графики
Мы начнем с базовых концептуальных графиков, чтобы объяснить принцип работы векторных баз данных, а затем проведем конкретный анализ случая. Ниже приведено описание этих двух частей:
Объяснение принципа работы с помощью графиков
- График преобразования векторов: этот график показывает, как текстовые, графические или звуковые данные преобразуются в векторы.
- График векторного пространства: в многомерном пространстве каждая точка представляет собой вектор, и этот график показывает, как эти точки группируются по схожести. Мы можем использовать точки разных цветов для обозначения различных категорий данных.
- График процесса обработки запросов: от ввода запроса пользователем до получения результата, этот график показывает весь процесс поиска. Он включает ввод запроса пользователем, процесс преобразования в вектор, процесс сопоставления векторов в базе данных и окончательный возврат пользователю схожих результатов.
Конкретный анализ случая
Предположим, что у нас есть компания электронной коммерции, которая хочет повысить точность и эффективность своей «системы рекомендаций продуктов», чтобы при поиске пользователем продукта можно было быстро найти и рекомендовать наиболее релевантные продукты.
Шаги выполнения случая:
- Сбор данных: компания собирает данные из своей базы данных продуктов, включая описания продуктов, изображения и отзывы клиентов.
- Преобразование векторов: с помощью модели машинного обучения описания и изображения каждого продукта преобразуются в векторы.
- Создание векторной базы данных: эти векторы хранятся в векторной базе данных, и создается система быстрого поиска.
- Обработка пользовательского запроса: когда пользователь вводит ключевой запрос, например, «кроссовки», система преобразует этот запрос в вектор и ищет в векторной базе данных наиболее похожие векторы.
- Возврат результата: система преобразует вектор продукта с наибольшей схожестью обратно в информацию о продукте и отображает ее пользователю.
Мы будем использовать Python для описания этих концепций. Давайте посмотрим на первый график: график преобразования векторов.
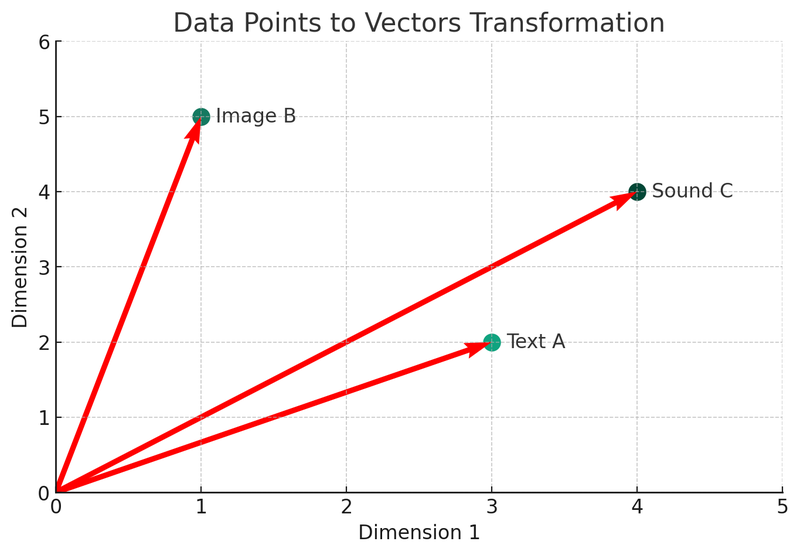
На этой иллюстрации мы видим, как три разных типа данных (текст A, изображение B, звук C) преобразуются в векторы в двумерном пространстве. Каждая точка представляет собой вектор, то есть математическое представление исходных данных. Этот процесс является основой для создания индексов и механизмов поиска в векторных базах данных.
Далее мы нарисуем второй график: график векторного пространства, который показывает, как эти точки данных (теперь векторы) группируются по схожести в многомерном пространстве.
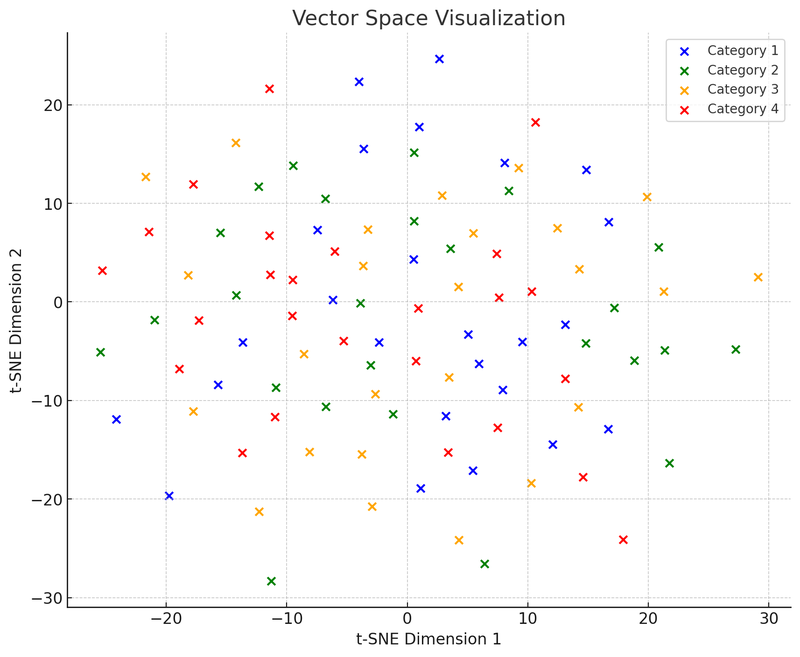
На этой визуализации векторного пространства мы используем t-SNE (t-distributed Stochastic Neighbor Embedding), популярную технику уменьшения размерности, которая помогает проецировать высокоразмерные данные в двумерное или трехмерное пространство для визуализации. Этот график показывает распределение 100 точек данных (изначально в 50-мерном пространстве) после уменьшения размерности до двумерного пространства. Предположим, что эти точки разделены на четыре категории, каждая из которых обозначена разным цветом. Такая визуализация помогает понять, как работают векторные базы данных: они могут группировать схожие точки данных (векторы) вместе на основе их относительных расстояний. Эта особенность позволяет векторным базам данных быстро находить «соседние» точки при поиске, то есть те точки данных, которые наиболее похожи на запрос.
Чтобы смоделировать систему рекомендаций продуктов компании электронной коммерции, мы создадим упрощенный пример, включающий: набор векторов продуктов и вектор запроса пользователя. Мы визуализируем распределение этих векторов продуктов в векторном пространстве и покажем, как «вектор запроса» пользователя находит «ближайший вектор продукта», чтобы объяснить применение векторных баз данных в системе рекомендаций продуктов.
Визуализированный анализ случая
Сначала создаем набор симулированных векторов продуктов, затем определяем вектор запроса пользователя. Затем мы покажем на графике, как этот вектор запроса находит ближайший вектор продукта в векторном пространстве.
Давайте начнем этот процесс.
На этом графике синие точки представляют собой различные продукты на платформе электронной коммерции, и каждый продукт имеет двумерный вектор признаков. Красная точка — это запрос пользователя, который также преобразован в двумерный вектор. Мы используем структуру данных K-D дерево (KDTree), чтобы быстро найти «вектор продукта, ближайший к запросу пользователя».
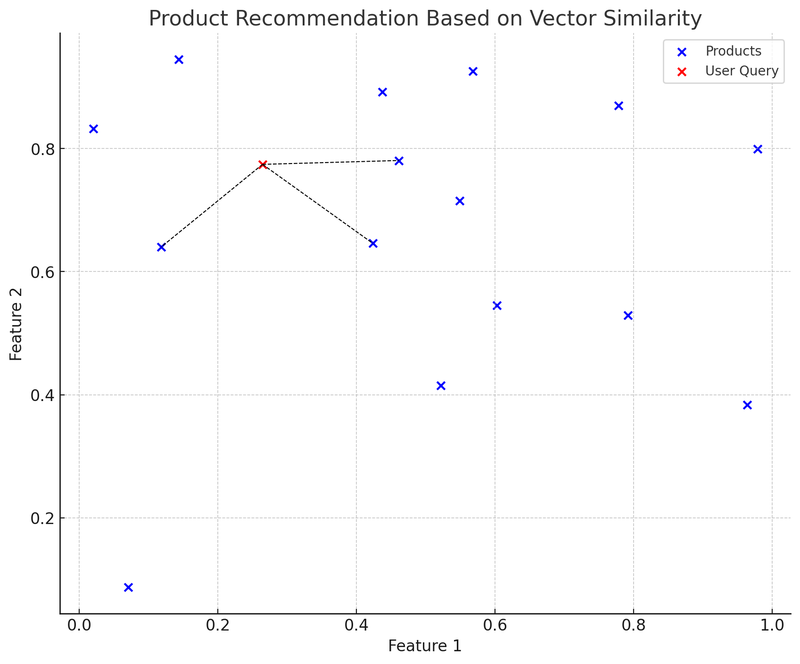
На графике линия (черная пунктирная) от вектора запроса пользователя (красная точка) до ближайшего вектора продукта показывает, что система рекомендаций будет рекомендовать эти продукты пользователю на основе схожести векторов. Это упрощенный пример применения векторных баз данных: пользователь делает запрос, система преобразует запрос в вектор и быстро находит в векторной базе данных наиболее похожий вектор продукта, чтобы рекомендовать соответствующие продукты пользователю.
Преимущество этого метода заключается в быстрой и относительно точной рекомендации, поскольку она основана на математическом расчете характеристик продукта, а не только на сопоставлении ключевых слов. Проблемы включают: как выбрать и настроить векторы признаков, чтобы лучше всего описывать и представлять характеристики продукта, а также как справляться с «холодным стартом» для новых продуктов или менее распространенных запросов.
Заключение
В современном бизнес-среде, где решения принимаются на основе данных, векторные базы данных обрабатывают и извлекают большие объемы многомерных данных уникальным и мощным образом, что делает их идеальным выбором для приложений искусственного интеллекта и машинного обучения. От повышения релевантности результатов поиска до продвижения персонализированных рекомендаций продуктов, векторные базы данных быстро становятся ценным инструментом для инженеров данных и технологических новаторов в различных отраслях. С помощью иллюстраций и анализа случаев от Appar Technologies мы надеемся, что смогли ясно объяснить, как работают векторные базы данных и почему они могут предоставлять такие быстрые и точные результаты.
Векторные базы данных демонстрируют, насколько мощными могут быть инструменты и приложения, когда люди начинают понимать и использовать данные по-новому. С развитием технологий мы можем ожидать, что векторные базы данных будут играть еще более важную роль в будущей обработке и анализе данных.
Если вас интересует, как генеративный ИИ может создавать качественные статьи, интегрировать большие языковые модели в продукты или внутренние процессы компании, свяжитесь с экспертами по генеративному ИИ Appar Technologies, hello@appar.com.tw для консультации.