Hva er en vektordatabaser?
By Sean Chen, 10. november 2023

Denne artikkelserien er en del av "La AI forklare AI", og hele teksten er skrevet av GPT-4 og andre store språkmodeller under menneskelig tilsyn. Serien er laget for å gi arbeidere med ulike bakgrunner en enkel måte å tilegne seg AI-relatert kunnskap på. Den første delen forklarer betydningen av kunnskapspunktet for forretningssiden, mens den andre delen forklarer mer tekniske detaljer.
Når virksomheter møter den store dataalderen, blir vektordatabaser et lys i mørket for ustrukturerte data, og lyser opp veien for rask informasjonsinnhenting. Denne artikkelen vil gi deg en dypere forståelse av hvordan denne teknologien fungerer, og hva den betyr for næringslivet.
Prinsippet og essensen av vektordatabaser
Vektordatabaser bruker matematiske "vektorer" for å lagre informasjon. La oss bruke et eksempel fra hverdagen for å illustrere: Tenk deg at du har mange små baller i forskjellige farger i rommet ditt, og hver ball representerer en type data. Nå vil du plassere ballene på bestemte steder på en bokhylle, og disse stedene skal kunne reflektere fargeegenskapene til hver ball. Du bestemmer deg for å bruke en "fargekart" notatbok for å hjelpe deg med å finne plasseringen til hver ball. I denne notatboken vil baller med lignende farger plasseres nær hverandre, mens de med forskjellige farger vil plasseres lengre fra hverandre.
Vektordatabaser fungerer på samme måte. De konverterer ulike typer data (som tekst, bilder eller lyd) til matematiske vektorer (som de nevnte ballene). Disse vektorene har sine egne posisjoner i et flerdimensjonalt rom, akkurat som ballene på bokhyllen. Når du ønsker å raskt finne data som ligner på en bestemt type data, vil vektordatabasen hjelpe deg med å finne vektoren som er nærmest i dette flerdimensjonale rommet (akkurat som å finne ballen med den nærmeste fargen).
Enkelt sagt, det handler om å bruke matematiske metoder for å abstrahere dataenes egenskaper til punkter i rommet, og deretter bruke beregninger av avstanden mellom disse punktene for raskt å finne lignende data.
Hvorfor det er viktig
Tenk deg at du er i et stort bibliotek og leter etter en bestemt bok. Hvis hver bok bare kan ordnes etter forfatter eller tittel, kan det ta mye tid å finne den. Men hvis bøkene er ordnet etter "innholdsrelevans", vil boken du leter etter være plassert sammen med bøker om lignende emner, noe som gjør det mye raskere å finne den. Dette er viktigheten av vektordatabase: De kan i stor grad forbedre effektiviteten ved å søke og analysere store mengder data.
Hvordan bruke det
Når du bruker en vektordatabaser, må du først ha et datasett, for eksempel tekst, bilder eller lyd. Disse dataene vil bli konvertert til "vektorer" gjennom "maskinlæringsmodeller". Deretter lagres disse vektorene i vektordatabasen. Når en bruker sender inn en forespørsel, blir forespørselen også konvertert til en vektor, og databasen vil raskt finne dataene som er nærmest denne forespørselsvektoren, og dermed finne informasjonen brukeren trenger.
Applikasjoner
Vektordatabase brukes av selskaper i ulike bransjer som trenger å håndtere store mengder data. Dette inkluderer teknologiselskaper, finansinstitusjoner, helseinstitusjoner og til og med forhandlere. Enhver organisasjon som trenger å "raskt finne nødvendig informasjon fra et hav av ustrukturerte data" kan bruke vektordatabase.
Fordeler
Fordelene med vektordatabase ligger i deres høye effektivitet og nøyaktighet. De kan raskt behandle og hente store mengder komplekse data, noe som ofte ikke er mulig med tradisjonelle databaser. I tillegg er vektordatabase svært gode til å håndtere uklare forespørsler, noe som er avgjørende for maskinlæring og kunstig intelligensapplikasjoner.
Utfordringer
De krever mye datakraft, spesielt når man håndterer svært store datasett. I tillegg trenger de høyt spesialisert kunnskap for å sette opp og vedlikeholde. Til slutt er personvern og datasikkerhet også viktige hensyn.
Etter å ha fått en grunnleggende forståelse av vektordatabase, la oss nå bruke diagrammer og virkelige eksempler for å få en mer konkret forståelse av hvordan vektordatabase fungerer!
Introduksjon til vektordatabase gjennom visuelle diagrammer
Vi starter med grunnleggende konseptdiagrammer for å forklare hvordan vektordatabase fungerer, og deretter utfører vi en konkret caseanalyse. Her er beskrivelsen av disse to delene:
Diagramforklaring av driftsprinsippet
- Vektorkonverteringsdiagram: Dette diagrammet viser hvordan tekst-, bilde- eller lyddata konverteres til vektorer.
- Vektorromdiagram: I et flerdimensjonalt rom representerer hvert punkt en vektor, og dette diagrammet vil vise hvordan disse punktene er gruppert sammen basert på likhet. Vi kan bruke punkter i forskjellige farger for å representere forskjellige datakategorier.
- Forespørselsbehandlingsflytdiagram: Fra brukerens inndata til å få resultatene, vil dette flytdiagrammet vise hele hentingsprosessen. Dette vil inkludere brukerens forespørsel, konverteringsprosessen til en vektor, samsvarsprosessen i databasen, og de endelige lignende resultatene som returneres til brukeren.
Konkret caseanalyse
Anta at det er et e-handelsselskap som ønsker å forbedre nøyaktigheten og effektiviteten til sitt "produktanbefalingssystem", med mål om at brukerne raskt skal finne og anbefale de mest relevante produktene når de søker etter produkter.
Caseutførelsestrinn:
- Datainnsamling: Selskapet samler inn data fra produktdatabasen, inkludert produktbeskrivelser, bilder og kundeanmeldelser.
- Vektorkonvertering: Ved hjelp av maskinlæringsmodeller konverteres hver produkts beskrivelse og bilde til vektorer.
- Opprettelse av vektordatabaser: Disse vektorene lagres i vektordatabasen, og et raskt hentesystem opprettes.
- Brukerforespørselsbehandling: Når en bruker skriver inn et søkeord, for eksempel joggesko, konverterer systemet denne forespørselen til en vektor og søker etter den mest lignende vektoren i vektordatabasen.
- Returnere resultater: Systemet konverterer produktvektoren med høyest likhet tilbake til produktinformasjon og viser den til brukeren.
Vi vil bruke Python for å beskrive disse konseptene. La oss se på det første diagrammet: Vektorkonverteringsdiagram.
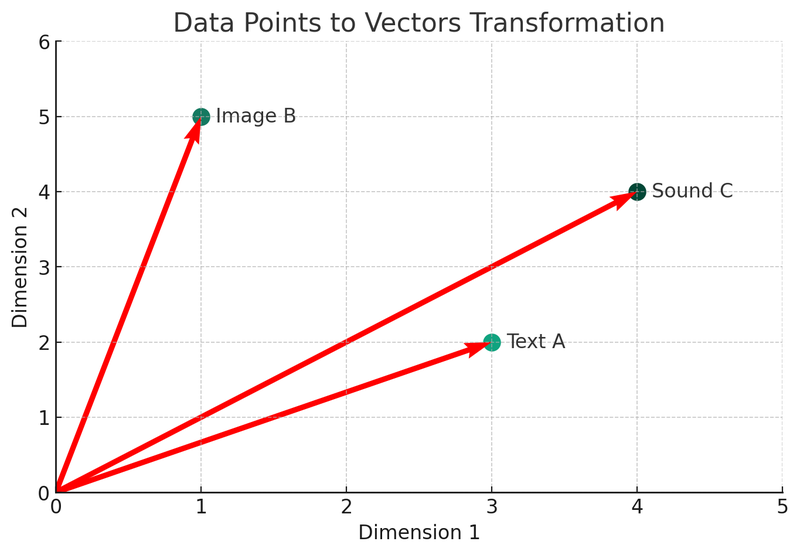
I denne illustrasjonen kan vi se tre forskjellige datatyper (tekst A, bilde B, lyd C) som er konvertert til vektorer i et todimensjonalt rom. Hvert punkt representerer en vektor, som er den matematiske representasjonen av de opprinnelige dataene. Denne prosessen er kjernen i vektordatabasens indekserings- og hentemekanisme.
Deretter vil vi tegne det andre diagrammet: Vektorromdiagrammet, som viser hvordan disse datapunktene (nå vektorer) er gruppert i et flerdimensjonalt rom basert på likhet.
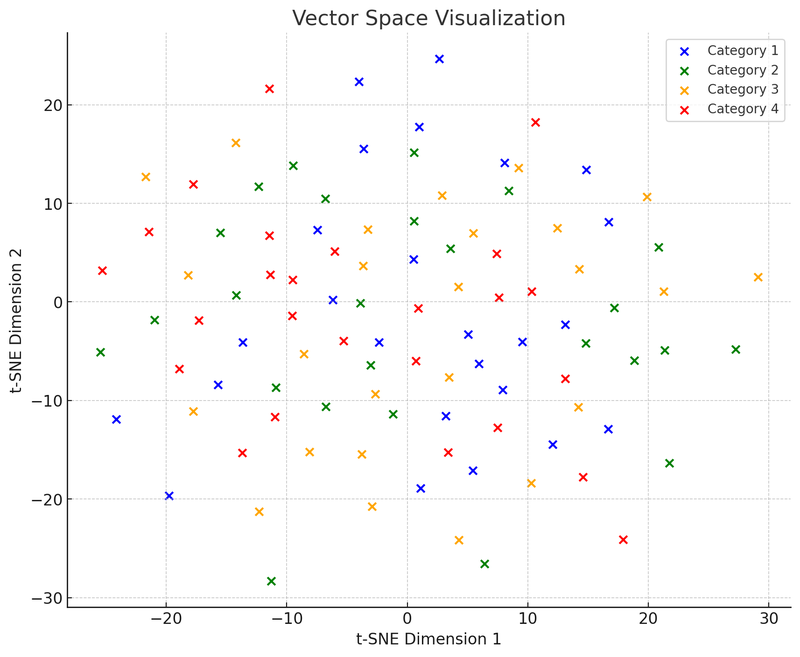
I denne visualiseringen av vektorrommet har vi brukt t-SNE (t-distributed Stochastic Neighbor Embedding), en vanlig dimensjonsreduksjonsteknikk som hjelper oss med å projisere høy-dimensjonale data til et to- eller tredimensjonalt rom for visualisering. Dette diagrammet viser fordelingen av 100 datapunkter (opprinnelig i et 50-dimensjonalt rom) etter dimensjonsreduksjon til et todimensjonalt rom. Anta at disse punktene er delt inn i fire kategorier, hver kategori representert med en annen farge. Slik visualisering hjelper oss med å forstå hvordan vektordatabase fungerer: De kan gruppere lignende datapunkter basert på den relative avstanden mellom dem. Denne egenskapen gjør at vektordatabase raskt kan finne "nabo"-punkter under henting, det vil si de datapunktene som er mest like forespørselen.
For å simulere et e-handelsselskaps produktanbefalingssystem, vil vi lage et forenklet eksempel som inkluderer: et sett med produktvektorer og en brukerforespørselsvektor. Vi vil bruke visualisering for å vise fordelingen av disse produktvektorene i vektorrommet og hvordan brukerens "forespørselsvektor" finner "nærmeste produktvektor", for å illustrere anvendelsen av vektordatabase i produktanbefalingssystemet.
Visualisert caseanalyse
Først genererer vi et sett med simulerte produktvektorer, og deretter definerer vi en brukerforespørselsvektor. Deretter vil vi
bruke et diagram for å vise hvordan denne forespørselsvektoren lokaliseres i vektorrommet og finner de nærmeste produktvektorene.
La oss starte denne prosessen.
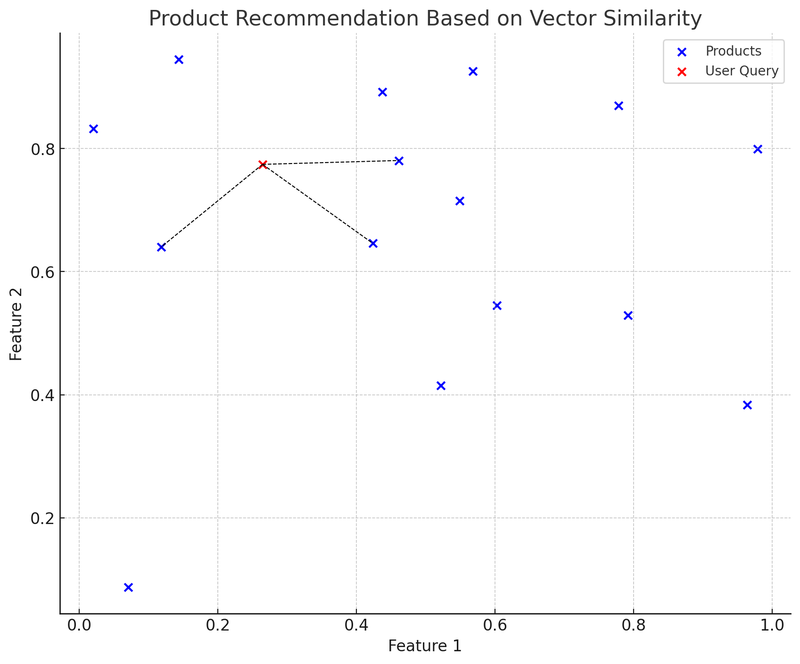
I dette diagrammet representerer de blå punktene ulike produkter på e-handelsplattformen, og hvert produkt har en todimensjonal funksjonsvektor. Det røde punktet er en brukers forespørsel, som også er konvertert til en todimensjonal vektor. Vi har brukt K-D Tree (KDTree) datastrukturen for raskt å finne produktvektoren som er nærmest "brukerens forespørsel".
I diagrammet representerer den svarte stiplete linjen fra brukerens forespørselsvektor (rødt punkt) til den nærmeste produktvektoren: Anbefalingssystemet vil anbefale disse produktene til brukeren basert på vektorsimilaritet. Dette er et forenklet eksempel på hvordan vektordatabase brukes i praksis: Brukeren sender inn en forespørsel, systemet konverterer forespørselen til en vektor, og finner raskt den mest lignende produktvektoren i vektordatabasen, for deretter å anbefale relevante produkter til brukeren.
Fordelen med denne metoden er at anbefalingene er raske og relativt nøyaktige, fordi de er basert på matematiske beregninger av produktfunksjoner, og ikke bare nøkkelordmatching. Utfordringene inkluderer: Hvordan velge og justere funksjonsvektorer for best å beskrive og representere produktegenskaper, samt hvordan håndtere "kaldstart"-problemet for nye produkter eller sjeldne forespørsler.
Konklusjon
I dagens datadrevne forretningsmiljø behandler og henter vektordatabase store mengder flerdimensjonale data på en unik og kraftig måte, noe som gjør dem til et ideelt valg for kunstig intelligens og maskinlæringsapplikasjoner. Fra å forbedre relevansen av søkeresultater til å drive personlig produktanbefaling, blir vektordatabase raskt et verdifullt verktøy for dataingeniører og teknologiske innovatører i ulike bransjer. Gjennom Appar Technologies sine illustrasjoner og caseanalyser, håper vi å tydelig forklare hvordan vektordatabase fungerer, og hvorfor de kan gi så raske og nøyaktige resultater.
Vektordatabase viser hvor kraftige verktøy og applikasjoner kan skapes når folk forstår og bruker data på nye måter. Etter hvert som teknologien fortsetter å utvikle seg, kan vi forvente at vektordatabase vil spille en enda mer kritisk rolle i fremtidens databehandling og analysearbeid.
Hvis du er interessert i hvordan generativ AI kan produsere høykvalitetsartikler, integrere store språkmodeller i produkter eller interne prosesser, kan du kontakte generativ AI-ekspert Appar Technologies, hello@appar.com.tw for å avtale en konsultasjon.