Co je to vektorová databáze?
By Sean Chen, 10. listopadu 2023

Tento článek je součástí série „Nechte AI vysvětlit AI“, celý text byl napsán pomocí velkých jazykových modelů jako GPT-4 pod lidským dohledem. Série je navržena tak, aby pracovníci z různých oborů mohli snadno doplnit své znalosti o AI. První část vysvětluje obchodní význam daného bodu znalostí, zatímco druhá část se zabývá technickými detaily.
Když se podniky setkávají s příchodem éry velkých dat, vektorové databáze se stávají majákem v neštrukturovaných datových souborech, osvětlujícím cestu k rychlému vyhledávání informací. Tento článek vás provede hlubším pochopením toho, jak tato technologie funguje a jaký má význam a dopad na podnikatelský svět.
Principy a podstata vektorových databází
Vektorové databáze používají matematické „vektory“ k ukládání informací. Představme si příklad ze života: máte v pokoji mnoho malých míčků různých barev, každý míček představuje určitý druh dat. Nyní chcete umístit míčky na konkrétní místo na polici, přičemž tato místa by měla odrážet barevné vlastnosti každého míčku. Rozhodnete se použít „barevnou mapu“ jako poznámkový blok, který vám pomůže najít místo pro každý míček. V tomto poznámkovém bloku budou míčky podobných barev umístěny blíže k sobě, zatímco míčky různých barev budou umístěny dále od sebe.
Vektorové databáze fungují na stejném principu, nejprve převádějí různé druhy dat (jako text, obrázky nebo zvuk) na matematické vektory (jako zmíněné míčky). Tyto vektory mají své vlastní umístění v mnohorozměrném prostoru, podobně jako míčky na polici. Když chcete rychle najít data, která jsou nejpodobnější určitému datu, vektorová databáze vám pomůže najít v tomto mnohorozměrném prostoru vektory, které jsou nejblíže (jako hledání míčků s nejpodobnější barvou).
Jednoduše řečeno, jde o matematickou metodu, která abstrahuje vlastnosti dat do bodů v prostoru a pomocí výpočtu vzdáleností mezi těmito body rychle najde podobná data.
Proč je to důležité
Představte si, že hledáte konkrétní knihu ve velké knihovně, pokud by byly knihy seřazeny pouze podle autora nebo názvu, mohli byste strávit spoustu času hledáním. Ale pokud by byly knihy seřazeny podle „obsahové relevance“, kniha, kterou hledáte, by byla umístěna vedle knih s podobným tématem, což by hledání značně urychlilo. To je důležitost vektorových databází: mohou výrazně zvýšit efektivitu vyhledávání a analýzy velkého množství dat.
Jak používat
Při používání vektorové databáze je nejprve potřeba mít sadu dat, například text, obrázky nebo zvuk. Tato data jsou pomocí „modelu strojového učení“ převedena na „vektory“. Tyto vektory jsou pak uloženy ve vektorové databázi. Když uživatel zadá dotaz, tento dotaz je také převeden na vektor a databáze rychle najde datové vektory, které jsou nejblíže tomuto dotazovému vektoru, čímž najde informace, které uživatel potřebuje.
Aplikace
Vektorové databáze jsou používány společnostmi v různých odvětvích, které potřebují zpracovávat velké množství dat. To zahrnuje technologické společnosti, finanční instituce, zdravotnické organizace a dokonce i maloobchodníky. Jakákoli organizace, která potřebuje rychle najít potřebné informace v „moři obtížně strukturovatelných dat“, může využít vektorové databáze.
Výhody
Výhodou vektorových databází je jejich vysoká efektivita a přesnost. Mohou rychle zpracovávat a vyhledávat velké množství složitých dat, což je často nemožné při použití tradičních databází. Navíc jsou vektorové databáze vynikající při zpracování nejasných dotazů, což je klíčové pro aplikace strojového učení a umělé inteligence.
Výzvy
Vyžadují velké množství výpočetních zdrojů, zejména při zpracování velmi velkých datových sad. Dále potřebují vysoce specializované znalosti pro nastavení a údržbu. Nakonec je důležitým faktorem také soukromí a bezpečnost dat.
Po základním pochopení vektorových databází se podívejme na vizuální grafy a konkrétní příklady, abychom lépe porozuměli jejich fungování!
Představení vektorových databází prostřednictvím vizuálních grafů
Začneme základními konceptuálními grafy, které vysvětlují principy fungování vektorových databází, a poté provedeme konkrétní případovou analýzu. Níže je popis těchto dvou částí:
Vysvětlení principů pomocí grafů
- Graf převodu vektorů: Tento graf ukazuje, jak jsou textová, obrazová nebo zvuková data převáděna na vektory.
- Graf vektorového prostoru: V mnohorozměrném prostoru každý bod představuje vektor, tento graf ukazuje, jak jsou tyto body seskupeny podle podobnosti. Můžeme použít různé barvy bodů k označení různých kategorií dat.
- Graf procesu zpracování dotazů: Od zadání dotazu uživatelem až po získání výsledků, tento procesní graf ukazuje celý proces vyhledávání. To zahrnuje vstup uživatelského dotazu, proces převodu na vektor, proces párování vektorů v databázi a konečné vrácení podobných výsledků uživateli.
Konkrétní případová analýza
Představme si e-commerce společnost, která chce zvýšit přesnost a efektivitu svého „systému doporučování produktů“, s cílem, aby uživatelé při hledání produktů rychle našli a doporučili nejrelevantnější produkty.
Kroky provedení případu:
- Sběr dat: Společnost sbírá data ze své produktové databáze, včetně popisů produktů, obrázků a hodnocení zákazníků.
- Převod vektorů: Pomocí modelu strojového učení jsou popisy a obrázky každého produktu převedeny na vektory.
- Vytvoření vektorové databáze: Tyto vektory jsou uloženy ve vektorové databázi a je vytvořen rychlý vyhledávací systém.
- Zpracování uživatelského dotazu: Když uživatel zadá klíčové slovo, například: sportovní boty, systém tento dotaz převede na vektor a vyhledá vektor, který je nejpodobnější ve vektorové databázi.
- Vrácení výsledků: Systém převede produktové vektory s nejvyšší podobností zpět na informace o produktech a zobrazí je uživateli.
Použijeme Python k popisu těchto konceptů. Podívejme se na první graf: graf převodu vektorů.
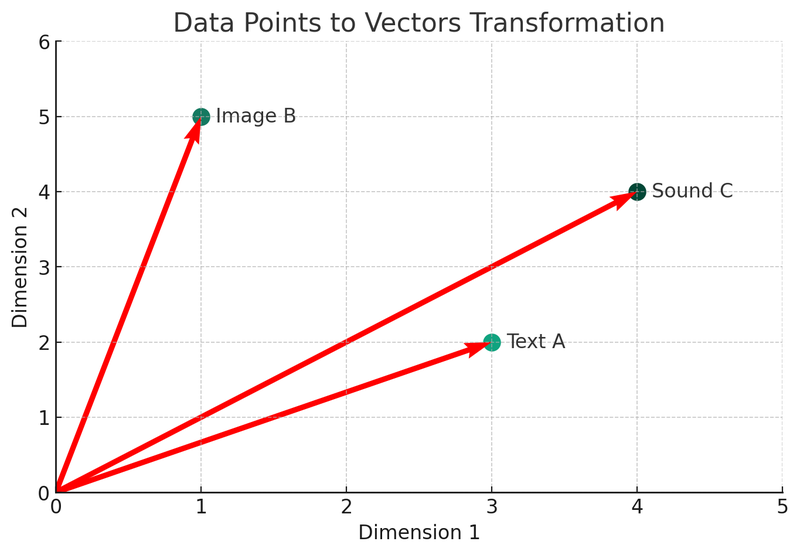
Na této ilustraci vidíme, jak jsou tři různé typy dat (text A, obrázek B, zvuk C) převedeny na vektory ve dvourozměrném prostoru. Každý bod představuje vektor, což je matematické vyjádření původních dat. Tento proces je jádrem vytváření indexů a vyhledávacích mechanismů vektorových databází.
Dále nakreslíme druhý graf: graf vektorového prostoru, který ukazuje, jak jsou tyto datové body (nyní vektory) seskupeny podle podobnosti v mnohorozměrném prostoru.
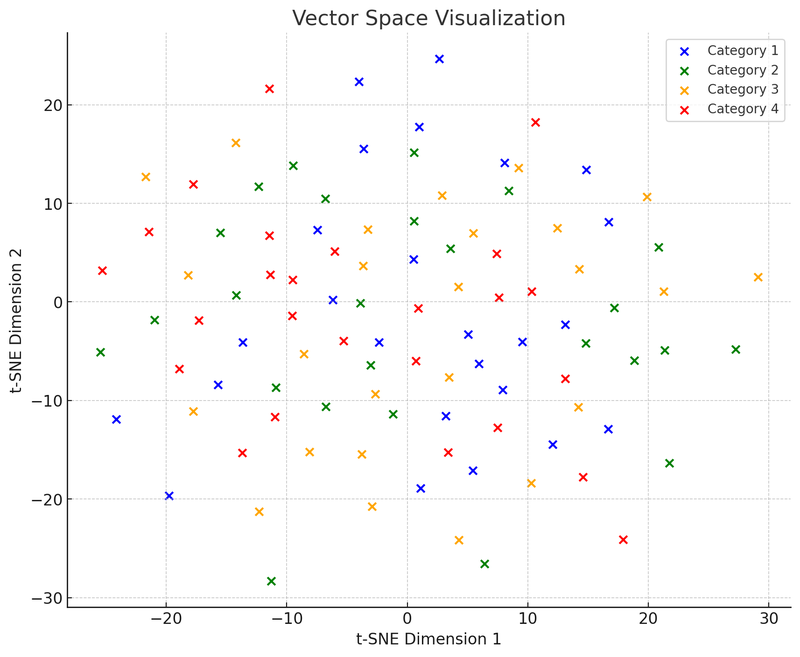
Na této vizualizaci vektorového prostoru jsme použili t-SNE (t-distributed Stochastic Neighbor Embedding), což je běžná technika pro snížení rozměrnosti, která nám pomáhá promítat data s vysokou rozměrností do dvourozměrného nebo trojrozměrného prostoru pro vizualizaci. Tento graf ukazuje rozložení 100 datových bodů (původně v 50rozměrném prostoru) po snížení rozměrnosti do dvourozměrného prostoru. Předpokládejme, že tyto body jsou rozděleny do čtyř kategorií, každá kategorie je označena jinou barvou, taková vizualizace pomáhá pochopit, jak vektorové databáze fungují: mohou seskupovat podobné datové body (tj. vektory) podle jejich relativní vzdálenosti. Tato vlastnost umožňuje vektorovým databázím rychle najít „sousední“ body při vyhledávání, tedy ty, které jsou nejpodobnější dotazu.
Pro simulaci systému doporučování produktů e-commerce společnosti vytvoříme zjednodušený příklad, který obsahuje: sadu produktových vektorů a uživatelský dotazový vektor. Pomocí vizualizace ukážeme rozložení těchto produktových vektorů ve vektorovém prostoru a jak uživatelský „dotazový vektor“ najde „nejbližší produktový vektor“, abychom vysvětlili aplikaci vektorových databází v systému doporučování produktů.
Vizualizovaná případová analýza
Nejprve vygenerujeme sadu simulovaných produktových vektorů a poté definujeme uživatelský dotazový vektor. Poté použijeme graf k zobrazení, jak tento dotazový vektor lokalizuje a najde nejbližší produktový vektor ve vektorovém prostoru.
Začněme tento proces.
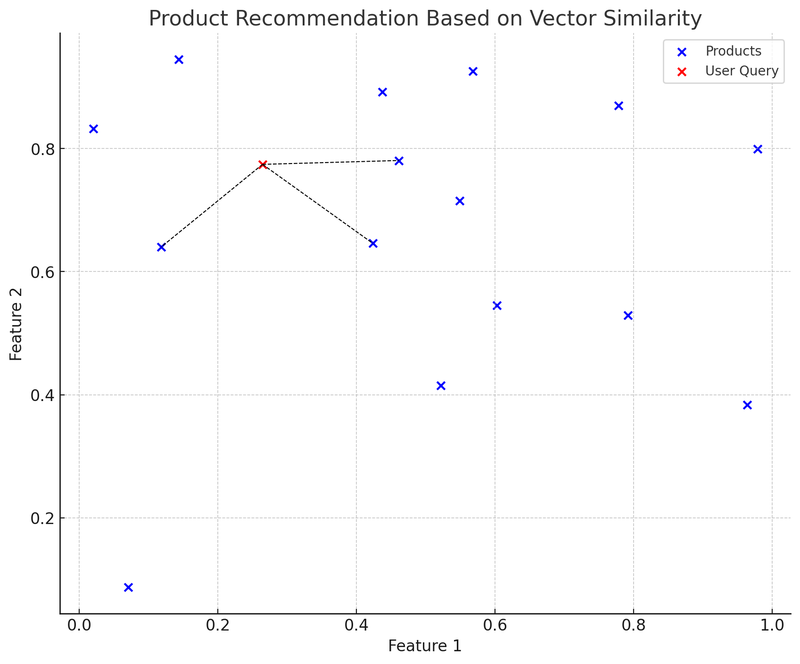
Na tomto grafu modré body představují jednotlivé produkty na e-commerce platformě, každý produkt má dvourozměrný vektor vlastností. Červený bod je uživatelský dotaz, který byl také převeden na dvourozměrný vektor. Použili jsme datovou strukturu K-D strom (KDTree) k rychlému nalezení produktového vektoru, který je „nejblíže uživatelskému dotazu“.
Na grafu černá přerušovaná čára spojuje uživatelský dotazový vektor (červený bod) s nejbližším produktovým vektorem, což znamená, že doporučovací systém doporučuje tyto produkty na základě podobnosti mezi vektory. Toto je zjednodušený příklad praktického použití vektorových databází: uživatel zadá dotaz, systém převede dotaz na vektor a rychle najde nejpodobnější produktový vektor ve vektorové databázi, čímž doporučí relevantní produkty uživateli.
Výhodou této metody je rychlost a relativní přesnost doporučení, protože je založena na matematickém výpočtu vlastností produktů, nikoli pouze na párování klíčových slov. Výzvy zahrnují: jak vybrat a upravit vektor vlastností, aby co nejlépe popisoval a reprezentoval vlastnosti produktu, a jak řešit problém „studeného startu“ (Cold Start) u nově uvedených produktů nebo méně častých dotazů.
Závěr
V dnešním obchodním prostředí řízeném daty vektorové databáze zpracovávají a vyhledávají velké množství mnohorozměrných dat jedinečným a silným způsobem, což z nich činí ideální volbu pro aplikace umělé inteligence a strojového učení. Od zvyšování relevance výsledků vyhledávání po podporu personalizovaných doporučení produktů se vektorové databáze rychle stávají cenným nástrojem pro datové inženýry a technologické inovátory v různých odvětvích. Doufáme, že prostřednictvím ilustrací a případových analýz od Appar Technologies jsme vám jasně vysvětlili, jak vektorové databáze fungují a proč mohou poskytovat tak rychlé a přesné výsledky.
Vektorové databáze ukazují, jak silné nástroje a aplikace lze vytvořit, když lidé začnou chápat a využívat data novými způsoby. S pokračujícím vývojem technologií můžeme očekávat, že vektorové databáze budou hrát stále klíčovější roli v budoucí práci s daty a analýzou.
Pokud máte zájem o to, jak generativní AI vytváří kvalitní články, integruje velké jazykové modely do produktů nebo interních procesů společnosti, můžete kontaktovat odborníky na generativní AI Appar Technologies, hello@appar.com.tw a domluvit si konzultaci.