Mi az a vektordatabase?
By Sean Chen, 2023. november 10.

Ez a cikksorozat az „AI magyarázza az AI-t” része, amelyet teljes egészében a GPT-4 és más nagy nyelvi modellek írtak emberi felügyelet mellett. A sorozat célja, hogy különböző háttérrel rendelkező szakemberek könnyedén bővíthessék AI-vel kapcsolatos ismereteiket. Az első rész a tudáspont üzleti jelentőségét magyarázza, míg a második rész mélyebb technikai részleteket tárgyal.
Amikor az üzleti világ találkozik a nagy adatok korszakával, a vektordatabase világítótornyot jelent a strukturálatlan adatok tengerében, megvilágítva a gyors információkeresés útját. Ez a cikk mélyrehatóan bemutatja, hogyan működik ez a technológia, és milyen jelentőséggel bír az üzleti világ számára.
A vektordatabase elve és lényege
A vektordatabase a matematikai „vektorokat” használja az információ tárolására. Vegyünk egy példát az életből: Tegyük fel, hogy a szobájában sok különböző színű golyó van, és minden golyó egy adatot képvisel. Most azt szeretné, hogy a golyókat a könyvespolc egy adott helyére tegye, és ezek a helyek tükrözzék a golyók színjellemzőit. Ezért úgy dönt, hogy egy „színtérkép” jegyzetfüzetet használ, hogy segítsen megtalálni minden golyó helyét. Ebben a jegyzetfüzetben a hasonló színű golyók közelebb kerülnek egymáshoz, míg a különböző színűek távolabb kerülnek.
A vektordatabase ugyanazon az elven működik: először különféle adatokat (például szöveget, képet vagy hangot) matematikai vektorokká alakít át (mint az említett golyók). Ezek a vektorok saját helyükkel rendelkeznek egy többdimenziós térben, mint a könyvespolcon lévő golyók. Amikor gyorsan szeretne megtalálni egy adott adathoz leginkább hasonló más adatokat, a vektordatabase segít megtalálni a legközelebbi vektorokat ebben a többdimenziós térben (mintha a legközelebbi színű golyókat keresné).
Egyszerűen fogalmazva, matematikai módszerekkel az adatok jellemzőit absztrakt pontokká alakítják a térben, majd ezeknek a pontoknak a távolságait kiszámítva gyorsan megtalálják a hasonló adatokat.
Miért fontos
Képzelje el, hogy egy nagy könyvtárban keres egy adott könyvet. Ha minden könyvet csak szerző vagy cím szerint rendeznek, rengeteg időt tölthet kereséssel. De ha a könyvek „tartalmi relevancia” szerint vannak rendezve, akkor a keresett könyv hasonló témájú könyvekkel együtt lesz, így sokkal gyorsabban megtalálható. Ez a vektordatabase fontossága: jelentősen növelheti a nagy mennyiségű adat keresésének és elemzésének hatékonyságát.
Hogyan használjuk
A vektordatabase használatához először szükség van egy adathalmazra, például szövegre, képre vagy hangra. Ezeket az adatokat „gépi tanulási modellek” segítségével „vektorokká” alakítják. Ezután ezeket a vektorokat a vektordatabase-ben tárolják. Amikor a felhasználó lekérdezést nyújt be, a lekérdezést szintén vektorrá alakítják, és a database gyorsan megtalálja a lekérdezési vektorhoz legközelebb álló adatvektorokat, így megtalálva a felhasználó által keresett információt.
Alkalmazások
A vektordatabase-t különböző iparágakban használják, ahol nagy mennyiségű adatot kell kezelni. Ide tartoznak a technológiai cégek, pénzügyi intézmények, egészségügyi szervezetek, sőt kiskereskedők is. Bármely szervezet, amelynek „strukturálatlan adatok tengeréből gyorsan kell információt találnia”, használhat vektordatabase-t.
Előnyök
A vektordatabase előnyei közé tartozik a nagy hatékonyság és pontosság. Gyorsan képes kezelni és visszakeresni nagy mennyiségű összetett adatot, ami hagyományos adatbázisokkal gyakran lehetetlen. Ezenkívül a vektordatabase kiválóan kezeli a homályos lekérdezéseket, ami elengedhetetlen a gépi tanulás és a mesterséges intelligencia alkalmazások számára.
Kihívások
Nagy számítási erőforrásokra van szükség, különösen nagyon nagy adathalmazok feldolgozásakor. Másodszor, magas szintű szakértelem szükséges a beállításhoz és karbantartáshoz. Végül, az adatok magánélete és biztonsága is fontos szempont.
A vektordatabase alapvető megértése után nézzük meg grafikusan és valós példákon keresztül, hogyan működik a vektordatabase!
Vektordatabase bemutatása vizuális diagramokkal
Kezdjük az alapvető koncepciódiagramokkal, hogy megmagyarázzuk a vektordatabase működési elvét, majd egy konkrét esettanulmányt végzünk. Az alábbiakban leírjuk ezt a két részt:
A működési elv diagramokkal való magyarázata
- Vektorátalakítási diagram: Ez a diagram bemutatja, hogyan alakítják át a szöveg-, kép- vagy hangadatokat vektorokká.
- Vektortér diagram: A többdimenziós térben minden pont egy vektort képvisel, és ez a diagram bemutatja, hogyan csoportosulnak ezek a pontok hasonlóság alapján. Különböző színű pontokkal jelölhetjük az adatok különböző kategóriáit.
- Lekérdezési folyamat diagram: A felhasználói lekérdezés beírásától az eredmények megszerzéséig ez a folyamatábra bemutatja az egész keresési folyamatot. Ez magában foglalja a felhasználói lekérdezés bevitelét, a vektorrá alakítás folyamatát, a vektorok adatbázisban történő párosítását, valamint a felhasználónak visszaküldött hasonló eredményeket.
Konkrét esettanulmány
Tegyük fel, hogy van egy e-kereskedelmi vállalat, amely javítani szeretné a „termékajánló rendszerének” pontosságát és hatékonyságát, azzal a céllal, hogy amikor a felhasználó termékeket keres, gyorsan megtalálja és ajánlja a legrelevánsabb termékeket.
Esettanulmány lépései:
- Adatgyűjtés: A vállalat összegyűjti az adatokat a termékadatbázisából, beleértve a termékleírásokat, képeket és vásárlói értékeléseket.
- Vektorátalakítás: Gépi tanulási modellek segítségével minden termék leírását és képét vektorokká alakítják.
- Vektordatabase létrehozása: Ezeket a vektorokat a vektordatabase-ben tárolják, és létrehoznak egy gyors keresési rendszert.
- Felhasználói lekérdezés feldolgozása: Amikor a felhasználó beír egy kulcsszó lekérdezést, például: sportcipő, a rendszer ezt a lekérdezést vektorrá alakítja, és a vektordatabase-ben megkeresi a leginkább hasonló vektorokat.
- Eredmények visszaküldése: A rendszer a legnagyobb hasonlóságú termékvektorokat visszaalakítja termékinformációkká, és megjeleníti a felhasználónak.
A koncepciók leírásához Python-t fogunk használni. Nézzük meg az első diagramot: vektorátalakítási diagram.
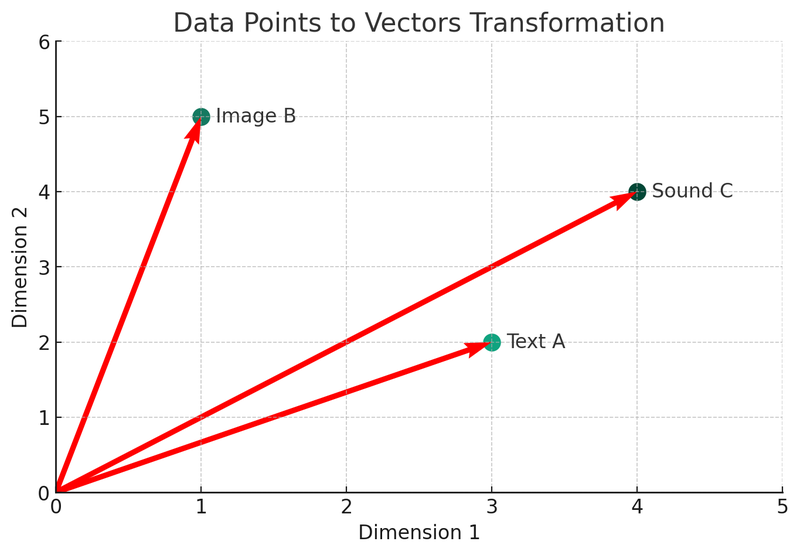
Ezen az ábrán három különböző adattípust (szöveg A, kép B, hang C) látunk, amelyek kétdimenziós térbeli vektorokká alakulnak. Minden pont egy vektort képvisel, azaz az eredeti adatok matematikai ábrázolását. Ez a folyamat a vektordatabase indexelési és keresési mechanizmusának magja.
Ezután megrajzoljuk a második diagramot: vektortér diagram, amely bemutatja, hogyan csoportosulnak ezek az adatpontok (most vektorok) a többdimenziós térben hasonlóság alapján.
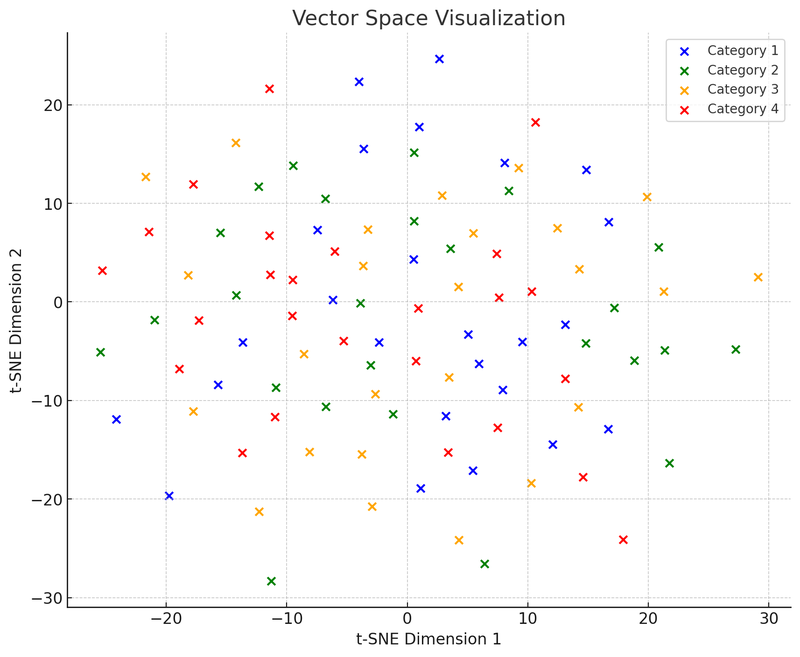
Ezen a vektortér vizualizációs ábrán t-SNE (t-distributed Stochastic Neighbor Embedding) technikát használtunk, amely egy gyakran alkalmazott dimenziócsökkentési technika, amely segít a magas dimenziós adatok kétdimenziós vagy háromdimenziós térbe való vetítésében a vizualizáció érdekében. Ez a diagram 100 adatpontot (eredetileg 50 dimenziós térben) mutat, amelyek kétdimenziós térbe való csökkentése után oszlanak el. Tegyük fel, hogy ezek a pontok négy kategóriába tartoznak, és minden kategóriát különböző színekkel jelölünk. Az ilyen vizualizáció segít megérteni, hogyan működik a vektordatabase: képesek az adatok pontjait (azaz vektorokat) a relatív távolságuk alapján csoportosítani, így a keresés során gyorsan megtalálják a „szomszédos” pontokat, azaz azokat, amelyek a lekérdezéshez leginkább hasonlóak.
Az e-kereskedelmi vállalat termékajánló rendszerének szimulálásához létrehozunk egy egyszerűsített példát, amely tartalmaz: egy termékvektor halmazt és egy felhasználói lekérdezési vektort. Grafikus módon bemutatjuk, hogyan oszlanak el ezek a termékvektorok a vektortérben, és hogyan találja meg a felhasználó „lekérdezési vektora” a „legközelebbi termékvektort”, hogy bemutassuk a vektordatabase alkalmazását a termékajánló rendszerben.
Grafikus esettanulmány
Először generálunk egy szimulált termékvektor halmazt, majd meghatározunk egy felhasználói lekérdezési vektort. Ezután egy diagramon bemutatjuk, hogyan helyezkedik el ez a lekérdezési vektor a vektortérben, és hogyan találja meg a legközelebbi termékvektort.
Kezdjük el ezt a folyamatot.
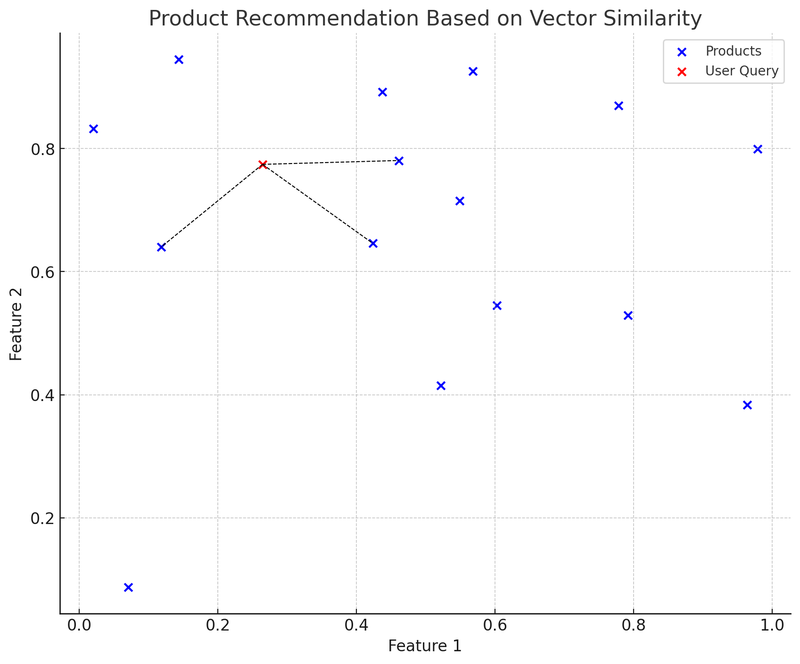
Ezen a diagramon a kék pontok az e-kereskedelmi platform különböző termékeit képviselik, minden terméknek van egy kétdimenziós jellemzővektora. A piros pont egy felhasználói lekérdezés, amelyet szintén kétdimenziós vektorrá alakítottak. A K-D fa (KDTree) adatstruktúrát használtuk, hogy gyorsan megtaláljuk a „felhasználói lekérdezéshez legközelebbi termékvektort”.
A diagramon a felhasználói lekérdezési vektortól (piros pont) a legközelebbi termékvektorig húzott vonal (fekete szaggatott vonal) azt jelzi, hogy az ajánlórendszer a vektorok közötti hasonlóság alapján ajánlja ezeket a termékeket a felhasználónak. Ez a vektordatabase gyakorlati alkalmazásának egy egyszerűsített példája: a felhasználó lekérdezést nyújt be, a rendszer a lekérdezést vektorrá alakítja, és a vektordatabase-ben gyorsan megtalálja a leginkább hasonló termékvektorokat, így ajánlva a kapcsolódó termékeket a felhasználónak.
Ennek a módszernek az előnye, hogy az ajánlás gyors és viszonylag pontos, mivel a termékjellemzők matematikai számításán alapul, nem csupán kulcsszó egyezésen. A kihívások közé tartozik: hogyan válasszuk ki és állítsuk be a jellemzővektorokat a termékjellemzők legjobb leírására, valamint hogyan kezeljük az újonnan felkerült termékek vagy ritkábban keresett lekérdezések „hidegindítási” (Cold Start) problémáját.
Következtetés
A mai adatvezérelt döntéshozatali üzleti környezetben a vektordatabase egyedi és erőteljes módon kezeli és keres nagy mennyiségű többdimenziós adatot, így ideális választássá válik a mesterséges intelligencia és a gépi tanulás alkalmazások számára. A keresési eredmények relevanciájának növelésétől a személyre szabott termékajánlások előmozdításáig a vektordatabase gyorsan a különböző iparágak adat mérnökei és technológiai újítói számára értékes eszközzé válik. Az Appar Technologies illusztrációi és esettanulmányai révén reméljük, hogy világosan bemutathattuk, hogyan működik a vektordatabase, és miért képes ilyen gyors és pontos eredményeket nyújtani.
A vektordatabase megmutatja, hogy amikor az emberek új módon értelmezik és használják az adatokat, milyen erőteljes eszközöket és alkalmazásokat hozhatnak létre. A technológia folyamatos fejlődésével várható, hogy a vektordatabase a jövőbeni adatfeldolgozási és elemzési munkákban még fontosabb szerepet fog játszani.
Ha érdekli, hogyan generál a generatív AI magas minőségű cikkeket, integrálja a nagy nyelvi modelleket a termékekbe vagy a vállalati belső folyamatokba, vegye fel a kapcsolatot a generatív AI szakértőivel Appar Technologies, hello@appar.com.tw időpont egyeztetéséhez.