Qu'est-ce qu'une base de données vectorielle ?
By Sean Chen, 10 novembre 2023

Cette série d'articles, intitulée « Laissez l'IA expliquer l'IA », est entièrement rédigée par des modèles de langage de grande taille comme GPT-4 sous supervision humaine. Cette série vise à fournir des connaissances sur l'IA de manière accessible à des professionnels de divers horizons. La première partie explique la signification commerciale du sujet, tandis que la seconde partie aborde des détails techniques plus approfondis.
Lorsque les entreprises rencontrent l'ère du big data, les bases de données vectorielles deviennent un phare dans l'océan des données non structurées, éclairant le chemin vers une recherche d'informations rapide. Cet article vous permettra de comprendre en profondeur comment cette technologie fonctionne et son impact sur le monde des affaires.
Principe et essence des bases de données vectorielles
Les bases de données vectorielles utilisent les « vecteurs » en mathématiques pour stocker des informations. Prenons un exemple de la vie quotidienne pour illustrer cela : supposons que votre chambre soit remplie de petites balles de différentes couleurs, chaque balle représentant une donnée. Maintenant, vous voulez placer ces balles sur une étagère à des positions spécifiques qui reflètent les caractéristiques de couleur de chaque balle. Vous décidez donc d'utiliser un carnet de « carte des couleurs » pour vous aider à trouver l'emplacement de chaque balle. Dans ce carnet, les balles de couleurs similaires sont placées plus près les unes des autres, tandis que celles de couleurs différentes sont placées plus loin.
Les bases de données vectorielles fonctionnent selon le même principe, elles convertissent d'abord divers types de données (comme du texte, des images ou des sons) en vecteurs mathématiques (comme les balles mentionnées précédemment). Ces vecteurs ont leur propre position dans un espace multidimensionnel, tout comme les balles sur l'étagère. Lorsque vous souhaitez rapidement trouver d'autres données similaires à une donnée spécifique, la base de données vectorielle vous aide à identifier les vecteurs les plus proches dans cet espace multidimensionnel (comme trouver les balles de couleur la plus proche).
En résumé, il s'agit d'abstraire les caractéristiques des données en points dans l'espace à l'aide de méthodes mathématiques, puis de calculer la distance entre ces points pour trouver rapidement des données similaires.
Pourquoi est-ce important
Imaginez que vous êtes dans une grande bibliothèque à la recherche d'un livre spécifique. Si chaque livre est uniquement classé par auteur ou titre, vous pourriez passer beaucoup de temps à chercher. Mais si les livres sont classés par « pertinence de contenu », le livre que vous voulez se trouvera avec d'autres livres sur des sujets similaires, ce qui rendra la recherche beaucoup plus rapide. C'est là que réside l'importance des bases de données vectorielles : elles peuvent considérablement améliorer l'efficacité de la recherche et de l'analyse de grandes quantités de données.
Comment utiliser
Pour utiliser une base de données vectorielle, vous devez d'abord disposer d'un ensemble de données, comme du texte, des images ou des sons. Ces données sont converties en « vecteurs » à l'aide de modèles d'apprentissage automatique. Ensuite, ces vecteurs sont stockés dans la base de données vectorielle. Lorsqu'un utilisateur effectue une requête, celle-ci est également convertie en vecteur, et la base de données trouve rapidement les vecteurs de données les plus proches de ce vecteur de requête, fournissant ainsi les informations recherchées par l'utilisateur.
Applications
Les bases de données vectorielles sont utilisées par des entreprises de divers secteurs qui doivent traiter de grandes quantités de données. Cela inclut les entreprises technologiques, les institutions financières, les établissements de santé, et même les détaillants. Toute organisation ayant besoin de « trouver rapidement les informations nécessaires dans un océan de données difficilement structurées » pourrait utiliser une base de données vectorielle.
Avantages
Les avantages des bases de données vectorielles résident dans leur efficacité et leur précision élevées. Elles peuvent traiter et récupérer rapidement de grandes quantités de données complexes, ce qui est souvent impossible avec les bases de données traditionnelles. De plus, les bases de données vectorielles excellent dans le traitement des requêtes floues, ce qui est crucial pour les applications d'apprentissage automatique et d'intelligence artificielle.
Défis
Elles nécessitent une grande quantité de ressources informatiques, en particulier lors du traitement de très grands ensembles de données. De plus, elles nécessitent des connaissances hautement spécialisées pour être configurées et maintenues. Enfin, la confidentialité et la sécurité des données sont également des considérations importantes.
Après avoir acquis une compréhension de base des bases de données vectorielles, passons à des graphiques et des cas concrets pour mieux comprendre leur fonctionnement !
Introduction aux bases de données vectorielles à travers des graphiques
Nous commencerons par un schéma conceptuel de base pour expliquer le fonctionnement des bases de données vectorielles, suivi d'une analyse de cas concret. Voici une description de ces deux parties :
Explication graphique du fonctionnement
- Schéma de conversion des vecteurs : Ce graphique montre comment les données textuelles, d'image ou sonores sont converties en vecteurs.
- Graphique de l'espace vectoriel : Dans un espace multidimensionnel, chaque point représente un vecteur, et ce graphique montre comment ces points sont regroupés en fonction de leur similarité. Nous pouvons utiliser des points de différentes couleurs pour représenter différentes catégories de données.
- Diagramme de traitement des requêtes : Du moment où l'utilisateur saisit une requête jusqu'à l'obtention du résultat, ce diagramme montre l'ensemble du processus de recherche. Cela inclut la saisie de la requête par l'utilisateur, sa conversion en vecteur, le processus de correspondance des vecteurs dans la base de données, et enfin les résultats similaires renvoyés à l'utilisateur.
Analyse de cas concret
Supposons qu'une entreprise de commerce électronique souhaite améliorer la précision et l'efficacité de son « système de recommandation de produits », avec pour objectif que lorsque les utilisateurs recherchent un produit, ils puissent rapidement trouver et recommander les produits les plus pertinents.
Étapes de mise en œuvre du cas :
- Collecte de données : L'entreprise collecte des données de sa base de données de produits, y compris les descriptions de produits, les images et les avis des clients.
- Conversion des vecteurs : À l'aide de modèles d'apprentissage automatique, chaque description et image de produit est convertie en vecteur.
- Création de la base de données vectorielle : Ces vecteurs sont stockés dans une base de données vectorielle, et un système de recherche rapide est mis en place.
- Traitement des requêtes utilisateur : Lorsqu'un utilisateur saisit une requête par mot-clé, par exemple : chaussures de sport, le système convertit cette requête en vecteur et recherche les vecteurs les plus similaires dans la base de données vectorielle.
- Retour des résultats : Le système convertit les vecteurs de produits les plus similaires en informations produit et les affiche à l'utilisateur.
Nous utiliserons Python pour décrire ces concepts. Regardons le premier graphique : le schéma de conversion des vecteurs.
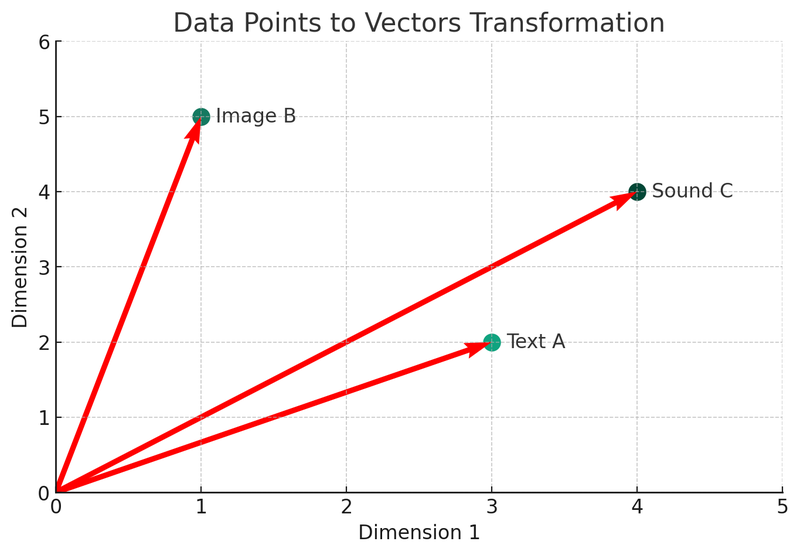
Dans cette illustration, nous pouvons voir trois types de données différents (texte A, image B, son C) convertis en vecteurs dans un espace bidimensionnel. Chaque point représente un vecteur, c'est-à-dire la représentation mathématique des données d'origine. Ce processus est au cœur du mécanisme d'indexation et de recherche des bases de données vectorielles.
Ensuite, nous allons dessiner le deuxième graphique : le graphique de l'espace vectoriel, montrant comment ces points de données (qui sont maintenant des vecteurs) sont regroupés par similarité dans un espace multidimensionnel.
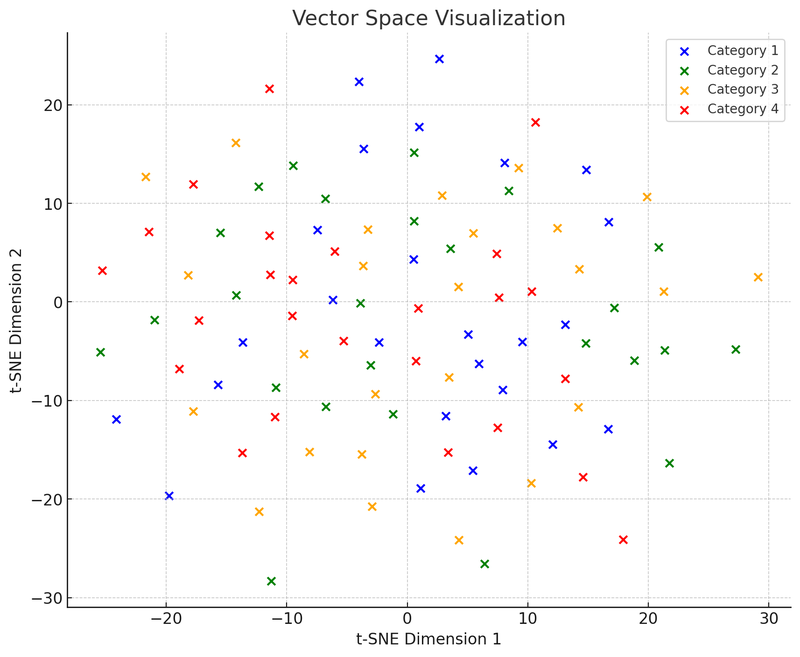
Dans cette illustration de l'espace vectoriel, nous avons utilisé t-SNE (t-distributed Stochastic Neighbor Embedding), une technique de réduction de dimension couramment utilisée, qui nous aide à projeter des données de haute dimension dans un espace bidimensionnel ou tridimensionnel pour la visualisation. Ce graphique montre la distribution de 100 points de données (initialement dans un espace de 50 dimensions) après réduction à un espace bidimensionnel. Supposons que ces points soient divisés en quatre catégories, chaque catégorie étant représentée par une couleur différente. Cette visualisation aide à comprendre comment fonctionnent les bases de données vectorielles : elles peuvent regrouper des points de données similaires (c'est-à-dire des vecteurs) en fonction de la distance relative entre eux. Cette caractéristique permet aux bases de données vectorielles de trouver très rapidement les points « voisins » lors de la recherche, c'est-à-dire ceux qui sont les plus similaires à la requête.
Pour simuler le système de recommandation de produits d'une entreprise de commerce électronique, nous allons créer un exemple simplifié comprenant : un ensemble de vecteurs de produits et un vecteur de requête utilisateur. Nous allons montrer graphiquement la distribution de ces vecteurs de produits dans l'espace vectoriel et comment le « vecteur de requête » de l'utilisateur trouve le « vecteur de produit le plus proche », pour illustrer l'application des bases de données vectorielles dans le système de recommandation de produits.
Analyse de cas graphique
Tout d'abord, générez un ensemble de vecteurs de produits simulés, puis définissez un vecteur de requête utilisateur. Ensuite, nous utiliserons un graphique pour montrer comment ce vecteur de requête se positionne dans l'espace vectoriel et trouve le vecteur de produit le plus proche.
Commençons ce processus.
Lançons-nous.
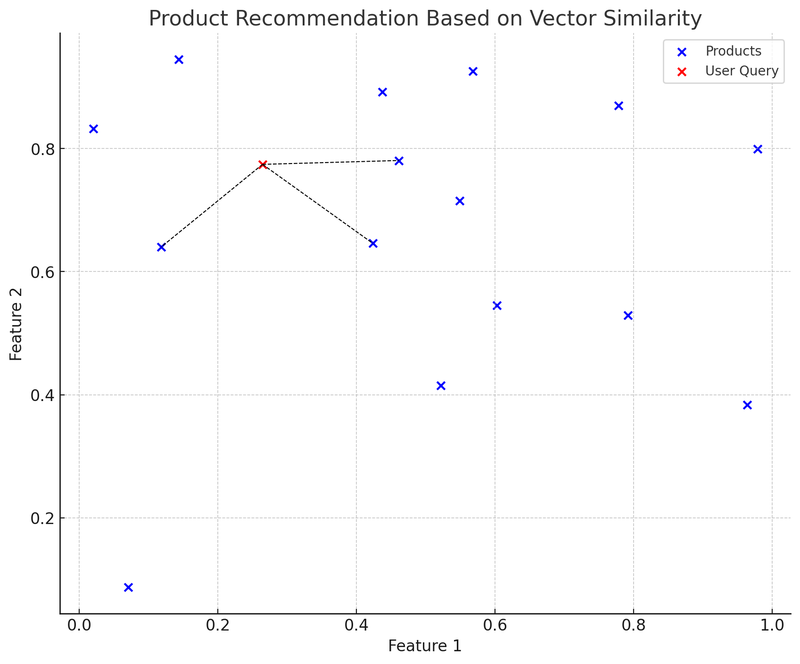
Dans ce graphique, les points bleus représentent les différents produits sur la plateforme de commerce électronique, chaque produit ayant un vecteur de caractéristiques bidimensionnel. Le point rouge est une requête utilisateur, qui a également été convertie en un vecteur bidimensionnel. Nous avons utilisé la structure de données K-D Tree (KDTree) pour trouver rapidement le « vecteur de produit le plus proche de la requête utilisateur ».
Dans le graphique, la ligne de connexion (ligne pointillée noire) du vecteur de requête utilisateur (point rouge) au vecteur de produit le plus proche indique que le système de recommandation recommandera ces produits à l'utilisateur en fonction de la similarité entre les vecteurs. C'est un exemple simplifié de l'application des bases de données vectorielles : l'utilisateur soumet une requête, le système la convertit en vecteur, et trouve rapidement le vecteur de produit le plus similaire dans la base de données vectorielle, recommandant ainsi des produits pertinents à l'utilisateur.
L'avantage de cette méthode est que la recommandation est rapide et relativement précise, car elle est basée sur des calculs mathématiques des caractéristiques des produits, et pas seulement sur la correspondance de mots-clés. Les défis incluent : comment choisir et ajuster les vecteurs de caractéristiques pour mieux décrire et représenter les caractéristiques des produits, et comment gérer le problème de « démarrage à froid » (Cold Start) pour les nouveaux produits ou les requêtes moins fréquentes.
Conclusion
Dans l'environnement commercial actuel axé sur les décisions basées sur les données, les bases de données vectorielles traitent et récupèrent de grandes quantités de données multidimensionnelles de manière unique et puissante, ce qui en fait un choix idéal pour les applications d'intelligence artificielle et d'apprentissage automatique. De l'amélioration de la pertinence des résultats de recherche à la promotion de recommandations de produits personnalisées, les bases de données vectorielles deviennent rapidement un outil précieux pour les ingénieurs de données et les innovateurs technologiques de divers secteurs. Grâce aux illustrations et analyses de cas d'Appar Technologies, nous espérons vous avoir clairement expliqué comment fonctionnent les bases de données vectorielles et pourquoi elles peuvent fournir des résultats aussi rapides et précis.
Les bases de données vectorielles montrent à quel point des outils et applications puissants peuvent être créés lorsque les gens comprennent et utilisent les données de nouvelles manières. Avec le développement continu de la technologie, nous pouvons nous attendre à ce que les bases de données vectorielles jouent un rôle encore plus crucial dans le traitement et l'analyse des données à l'avenir.
Si vous êtes intéressé par la façon dont l'IA générative peut produire des articles de haute qualité, intégrer des modèles de langage de grande taille dans des produits ou des processus internes d'entreprise, vous pouvez contacter les experts en IA générative Appar Technologies, hello@appar.com.tw pour prendre rendez-vous pour une consultation.